This is very much a ‘thinking aloud’ post.
In October last year I posted Structure in Trip an article that described the social networks of articles in Trip, based on clickstream data. The analysis allowed me to produce graphs like the one below (based on the clickstream data of people searching for UTI.
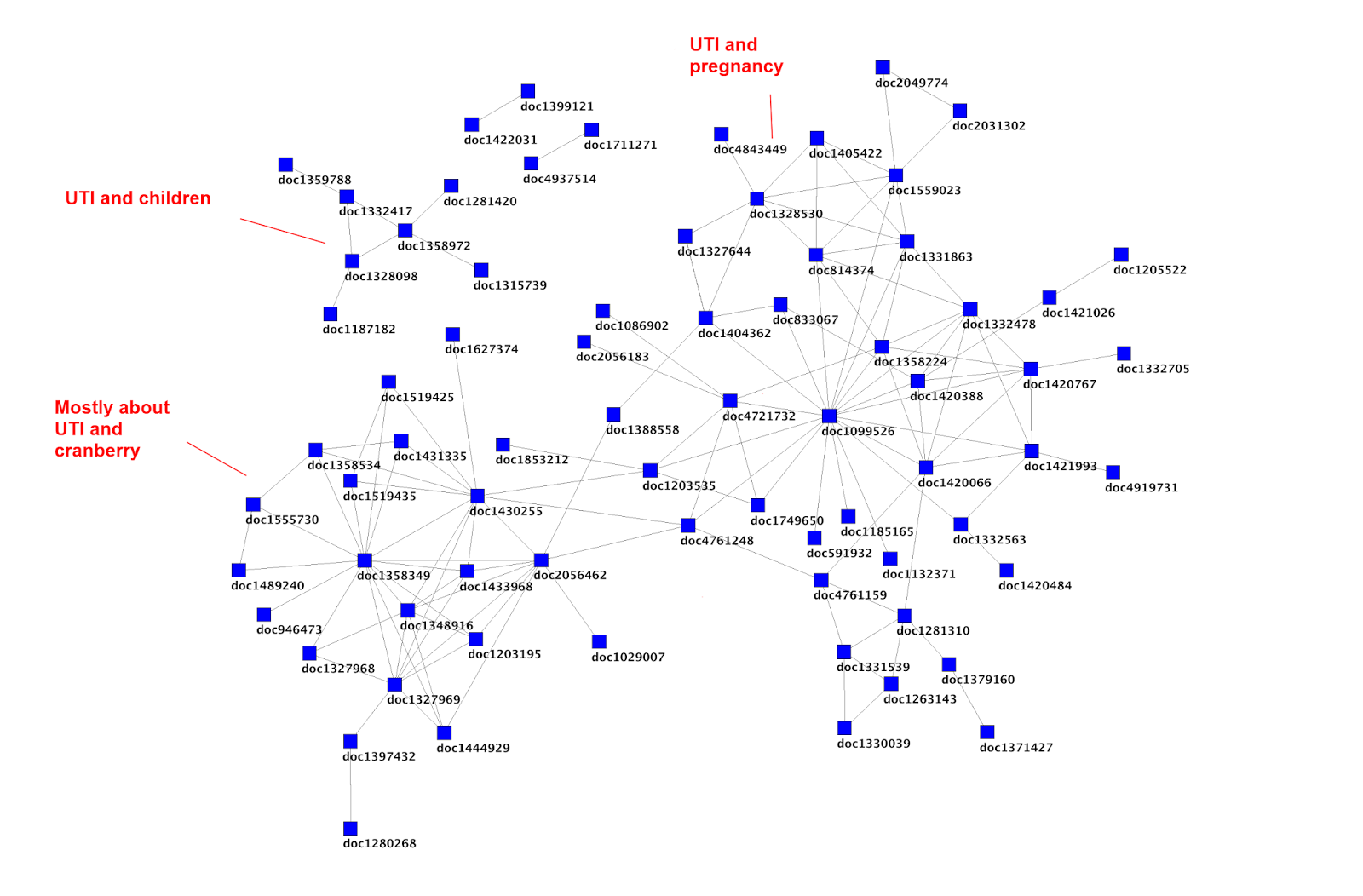
The structure is clear and I’ve labelled a few, the most prominent being UTIs and cranberry (in the bottom left of the graph).
I’m increasingly of the opinion that this can be used to speed up the review process and also improve the search experience (but search is for another day). In social network analysis there is a view that within a cluster there is a lot of duplicated information. If you think about your social networks your close friends probably know lots of the same things as you – this duplicated information/knowledge about birthdays, addresses etc. I can’t help feeling this is likely in clusters of articles. So, take the cluster of UTI and cranberry there’s probably a lot of duplicated information (background information I would have thought). But there is also lots of unique information (e.g. each set of results will be unique). Then the conclusions are probably split into three main types – positive, negative, uncertain/ambiguous.
So, as a precursor to more in-depth work I simply took the articles and created a word-cloud (I did do some editing to remove terms I felt were unhelpful):

And this is the thinking aloud part – I’m not sure if that’s helpful or even useful. It’s pretty. But I really don’t think it’s hugely helpful as it stands. However, it does take me further along with my thinking, I think! Perhaps adding some specialist semantic analysis would be helpful.
Now, and this surely constitutes a world first – an instant systematic review. I’ve posted a few times about five minute systematic reviews, but if we could identify clusters, extract the RCTs and automatically put them into our rapid review system the result is an instant review. Well, I did just that (manually, but it could be automated to make it truly instant). There were 18 articles in the UTI and cranberry cluster. Many of these were review articles but there were also 4 placebo-controlled trials. Placing them in our rapid review system gives the following result:

So, our system gives it a score of -0.12, so I would say that the results show no clear evidence for or against the effectiveness of cranberry juice in UTIs. One point, one of the trials is for a highly-specific population ‘patients undergoing radiotherapy for cancer of the bladder or cervix’ so ideally would be excluded.
How does our score of -0.12 compare with the Cochrane Cranberries for preventing urinary tract infections? Within their conclusion, they report:
“..cranberry juice cannot currently be recommended for the prevention of UTIs“
Lots of things to reflect on. I would say our conclusion is pretty much the same as Cochrane’s. Ours is based on far fewer trials. This, in part, reflects the fact that our cluster was only based on a small sample of all our data, so a full analysis would highlight more trials. But I think the principle is there, instant systematic reviews – easy!
I’m hoping I’ll look back at this post in 2-3 years time and laugh at how basic the analysis is – reflecting a significant leap forward in my work.

March 4, 2014 at 6:28 pm
Jon, how well did the clickstream data help you get to the trials here? Are there more relevant trials in TRIP? Would it change your conclusion if you add more trials from TRIP to the rapid review analysis?
LikeLike
January 15, 2015 at 6:33 pm
This is indeed fascinating, on a number of levels. However, there are several potential pitfalls to take into account.
Firstly, if I understand the methodology adequately (which is by no means certain!) we are looking at numerators here, without regard to denominators. This raises several confounding factors:
– the order that search results are presented will affect which papers are looked at, and in which order (i.e. there will be a systematic imposed bias).
– Also, there may be the effects of seeing what other people have done
– I'm not sure whether temporal data (i.e. how long on each page) are collected; this might turn out to be a measure of quality (instant rejects or 'accepts' cf prolonged inspection).
– it would be fascinating to have different types of user colour-coded (e.g. experience, clinician/academic, 1° or 2° care, etc) to see if this changes the patterns, or shows new one!.
LikeLike
January 15, 2015 at 7:03 pm
Hi Kit,
Thanks for the post. I've written a couple of new posts on the topic of networks, which you might enjoy:
1) Ok, I admit it, I'm stuck (https://blog.tripdatabase.com/2015/01/ok-i-admit-it-im-stuck.html)
2) People who looked at this article, also looked at… (https://blog.tripdatabase.com/2015/01/people-who-looked-at-this-article-also.html)
Temporal data is not collected as the person goes off from our site. I suppose you could measure the time between clicks! In academic search circles they typically rely on the last article being the most important – something I don't agree with!
As for different patterns – agreed. Using the UTI example comparing the network between GPs and urologists would indeed be fascinating.
I've got loads of ideas, just a lack of resource (money).
Happy to carry on the conversation via email (jon.brassey@tripdatabase.com) if you like!
LikeLike