In April 2013 I published A critique of Cochrane which was based on my presentation at Evidence Live 2013. This article has been read over 8,500 times and has opened up numerous separate discussions around systematic reviews and the nature of evidence. It’s still a topic I find fascinating and have moved my thinking on further.
This post follows my presentation at the Rethinking Evidence-Based Medicine: from rubbish to real meeting a short while ago….
In 2005 Richard Smith, former editor of the BMJ wrote the article Medical Journals Are an Extension of the Marketing Arm of Pharmaceutical Companies in Plos Medicine. It starts with a quote from the editor of The Lancet, Richard Horton, “Journals have devolved into information laundering operations for the pharmaceutical industry“. It’s well worth a read but the salient point is that journals are being co-opted by pharma to help push a skewed view of the research base for a given intervention. As Richard’s article states:
“The companies seem to get the results they want not by fiddling the results, which would be far too crude and possibly detectable by peer review, but rather by asking the “right” questions….but there are many ways to hugely increase the chance of producing favourable results, and there are many hired guns who will think up new ways and stay one jump ahead of peer reviewers.“
Recently he was on Twitter with the same message:
Another ‘trick’ is publication bias, so well presented in the Turner’s 2008 NEJM article Selective Publication of Antidepressant Trials and Its Influence on Apparent Efficacy. As Turner et al. point out:
“In the United States, the Food and Drug Administration (FDA) operates a registry and a results database. Drug companies must register with the FDA all trials they intend to use in support of an application for marketing approval or a change in labeling. The FDA uses this information to create a table of all studies. The study protocols in the database must prospectively identify the exact methods that will be used to collect and analyze data. Afterward, in their marketing application, sponsors must report the results obtained using the prespecified methods. These submissions include raw data, which FDA statisticians use in corroborative analyses. This system prevents selective post hoc reporting of favorable trial results and outcomes within those trials.”
So the FDA see many trials, but are these all published in peer-reviewed journals? The article reported that there were 38 studies favouring an antidepressant, of which 37 were published. Of the 36 that were negative, only 3 were published. If you do a meta-analysis on the published trials alone you get a distorted view and Turner compared a meta-analysis using FDA trials and published trials and found a 32% increase in effect size for meta-analyses of published trials versus FDA registered trials.
Tamiflu is another example and that raises even more issues. It is well worth reading more about it on the BMJ’s special Tamiflu webpage. The work that has gone on and is ongoing has highlighted further problems when relying on journal articles (published or unpublished). Articles are effectively summaries of the trial. Much more information is contained within the Clinical Study Report (CSR) – standardized documents representing the most complete record of the planning, execution, and results of clinical trials, which are submitted by industry to government drug regulators. I tend to view journals articles as abstracts of the CSR. So, an abstract is a summary of the journal article, the journal article is an abstract of a CSR. As abstracts are summaries they miss lots of data and in the case of Tamiflu when the authors looked at the CSRs they found lots of information about adverse events, discrepancies with blinding etc.
So, above I’ve highlighted two major issues that affect systematic reviews:
- Publication bias
- Using journal articles as opposed to CSRs
The AllTrials campaign is working very hard and with great success in trying to ensure more trials are published but it’s a work in progress, that’s for sure, and I hope that all readers of this article will support the campaign.
Publication bias and systematic reviews
But how do Cochrane deal with unpublished trials? Now, to clarify I think Cochrane do some great things and the thousands of volunteers work tirelessly to improve healthcare. In my previous article I was critical, but hopefully constructively so, and I will be again later in this article but it’d be rare for any large organisation to be perfect. Two further significant pluses about Cochrane:
- The Bill Silverman prize, started by Iain Chalmers (using his own money) which “acknowledges explicitly Cochrane’s value of criticism, with a view to helping to improve its work“. Iain himself asked me to submit my previous article for consideration for the prize.
- They are more transparent than any other systematic review producer. A lot of my criticisms were based on information from their own publications.
Anyway, back to Cochrane and unpublished trials. In 2013 Schroll, Bero and Gotzsche published Searching for unpublished data for Cochrane reviews: cross sectional study and concluded:
“Most authors of Cochrane reviews who searched for unpublished data received useful information, primarily from trialists. Our response rate was low and the authors who did not respond were probably less likely to have searched for unpublished data. Manufacturers and regulatory agencies were uncommon sources of unpublished data.“
In other words any unpublished trials found are unlikely to be from the manufacturers and any they do find are found in an un-systematic manner.
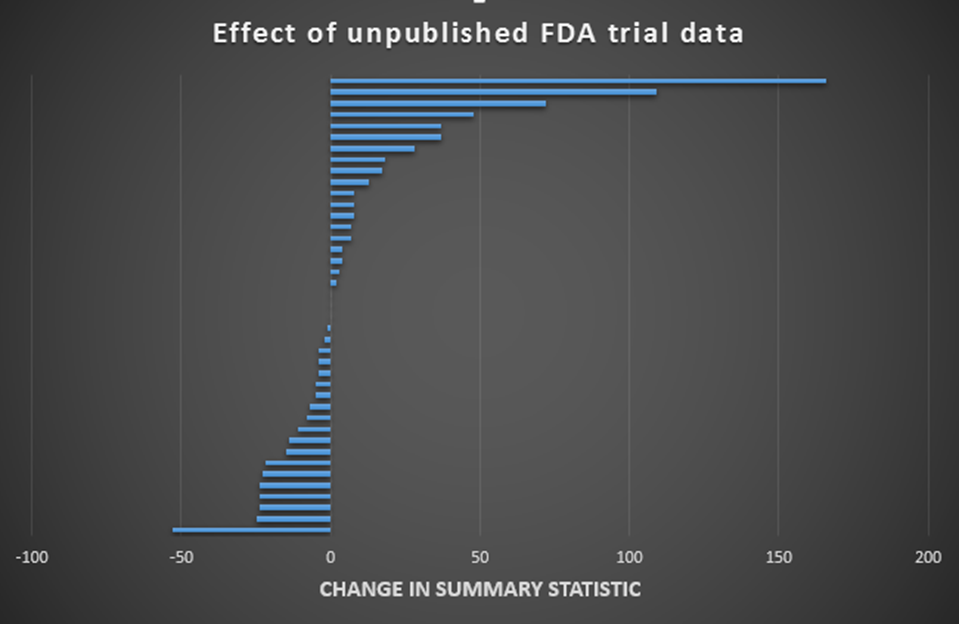
My cynicism/realism aside (delete depending on perspective) what does the evidence say about relying on published trials? The 2011 paper Effect of reporting bias on meta-analyses of drug trials: reanalysis of meta-analyses by Hart et al. used similar methods to Turner’s and compared meta-analyses of published trials versus meta-analyses of FDA data but over many more drugs/drug classes – 41 interventions in total. They reported:
“Overall, addition of unpublished FDA trial data caused 46% (19/41) of the summary estimates from the meta-analyses to show lower efficacy of the drug, 7% (3/41) to show identical efficacy, and 46% (19/41) to show greater efficacy.“
I charted the range of differences in effect size and that is shown below. I have zeroed the effect sizes of the meta-analyses based on published trials on the vertical zero line and the horizontal bars represent the discrepancy when using FDA data:
Quite a range. In just under 50% of the cases the discrepancy was greater than 10%. But what is equally troubling is the fact that the results are unpredictable. There is no way of knowing if the result of a meta-analysis, based on published trials, are likely to under-estimate or over-estimate the true effect size.
Clinical study reports and systematic reviews
As far as I can tell the Cochrane tamiflu review (proper title: Neuraminidase inhibitors for preventing and treating influenza in healthy adults and children) is the only Cochrane review to reject journal articles and only rely on CSRs. I am also unaware of any major systematic review producer that routinely uses CSRs (although some invariably will). However, I’m confident that the vast majority of systematic reviews avoid CSRs. The reasons are pragmatic, CSRs are massive documents with poor structure. Systematic reviews take an age using research articles, using CSRs would multiply the workload ten-fold (or even more).
Where does that leave us?
It is evident that systematic reviews cannot be relied upon for an accurate assessment of an average effect size for an intervention. The Hart paper (and others) has demonstrated that by including regulatory data it alters – in an unpredictable way – the estimate of effect of the intervention. So, if you see a systematic review with a given effect size there is an approximate 50% chance of the effect size being out by over 10% (not withstanding the chance that the systematic review is out of date). And, to reiterate this point, you’ve no way of knowing if the review is one of those reviews and if it is whether the estimate is under or over.
So, all I can conclude is that a systematic review gives a ball-park figure for the actual effect size. They are possibly the most accurate way of assessing likely effect size but who knows?
This is problematic for a large number of reasons, including:
- They take an awful lot of time and cost to arrive at this approximation. As I previously highlighted the workload on Cochrane is significant and only around a third of their reviews are up to date.
- Original Cochrane Reviews were not the massive beasts they are now. They were done quickly and were short. Over time, it appears to me, that methodologists have tried to eliminate bias from published data completely ignoring the likely larger effect of missing data bias and also the implication on workload of each new trick they roll out. But to what end? Accuracy?
- We use systematic reviews as a heuristic for accuracy. I have used myself and heard many others say something along the lines of ‘There’s a recent Cochrane systematic review, so no need to look any further‘. It is very easy, and convenient, to uncritically accept a review’s findings. This point is perhaps no-ones fault. I assumed systematic reviews were accurate and I suppose they are in that they invariable are good at saying if the intervention is good, bad or indifferent. But, if you want an estimate of effect – they simply don’t deliver in a predictable way. And confidence intervals don’t adequately represent the uncertainty as they are based on the included trials, they cannot and do not estimate uncertainty based on the 30-50% of missing trials.
So, the future is very much as laid out in my initial post, arguably the case is more compelling than ever.
I often wonder, due to the problems highlighted above, if giving an effect size, framed by narrow confidence intervals is mis-leading. Can we really say any more than ‘This is likely to effective and the effect size is likely to be in the range of…’? That seems more honest to me. I do feel much of the ‘problem’ I have with systematic reviews are linked to my perception. Systematic reviews producers probably don’t say that they produce accurate results, it’s assumed. But, they probably don’t do enough to highlight the shortcomings either. Accuracy sells, ballpark doesn’t.
Finally, a bit of mischief based on the assumption that 30-50% of trials are never reported…




Recent Comments