For many years I’ve admired PubMed’s related articles feature. If I was searching for an answer to a clinical question and found a useful article, related articles was a great way to see similar articles. These similar articles had a good chance of being useful as they were so similar. PubMed has no renamed the feature Similar Articles and this is what it does:
The Similar Articles link is as straightforward as it sounds. PubMed uses a powerful word-weighted algorithm to compare words from the Title and Abstract of each citation, as well as the MeSH headings assigned. The best matches for each citation are pre-calculated and stored as a set.
Trip’s related articles use a completely different approach – clickstream data. Does it matter? Does it work as well, worse or better?
Below are three comparisons. But these are not necessarily fair. For instance, Trip’s approach relies on users clicking on the articles – so it won’t work on brand new articles. Also, as you’ll see below a couple of the examples only have 4 related articles. This is down to paucity of data.
In the examples below I believe that Trip’s approach is superior but I’m not sure with the other two examples, I’d call it close! But I’d value any input from others – those less biased than me!
Bottom line: it’s a really powerful demonstration of the potential of clickstream data but requires data, another reason to log in to Trip!
One final point, this approach is phase 1. Phase 2 will be to start to use an approach closer to PubMed’s – using linguistic and semantic approaches.
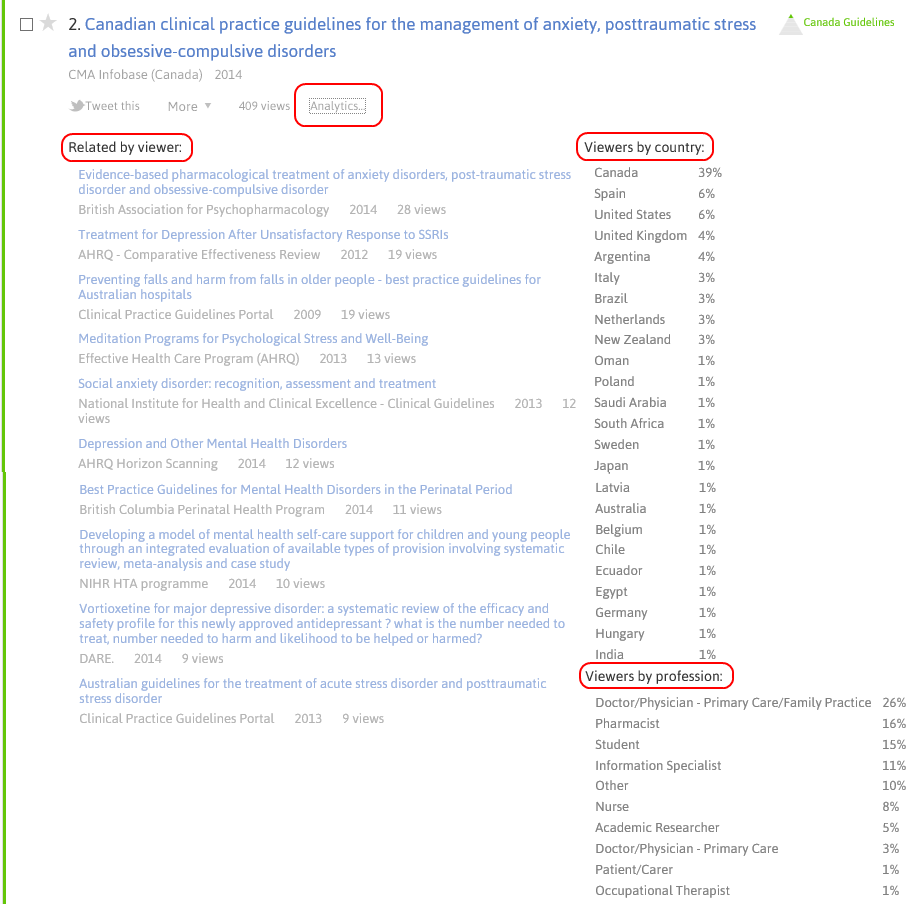
Paper 1: Screening for prostate cancer. Cochrane 2013
PubMed’s related articles
- Screening for prostate cancer. Cochrane Database Syst Rev. 2013
- Screening for prostate cancer. Cochrane Database Syst Rev. 2006
- Lycopene for the prevention of prostate cancer. Cochrane Database Syst Rev. 2011
- Prophylactic platelet transfusion for prevention of bleeding in patients with haematological disorders after chemotherapy and stem cell transplantation. Cochrane Database Syst Rev. 2012
- Chemoprevention of colorectal cancer: systematic review and economic evaluation. Health Technol Assess. 2010
Trip’s related articles
- Screening for prostate cancer: a review of the evidence for the U.S. Preventive Services Task Force DARE. 2011
- Population screening for prostate cancer: an overview of available studies and meta-analysis. DARE. 2012
- PSA Test to Screen for Prostate Cancer. theNNT 2011
- Update of evidence for prostate-specific antigen (PSA) testing in asymptomatic men. New Zealand Guidelines Group 2010
- Focal therapy using high-intensity focused ultrasound (HIFU) for localised prostate cancer. National Institute for Health and Clinical Excellence – Interventional Procedures 2012
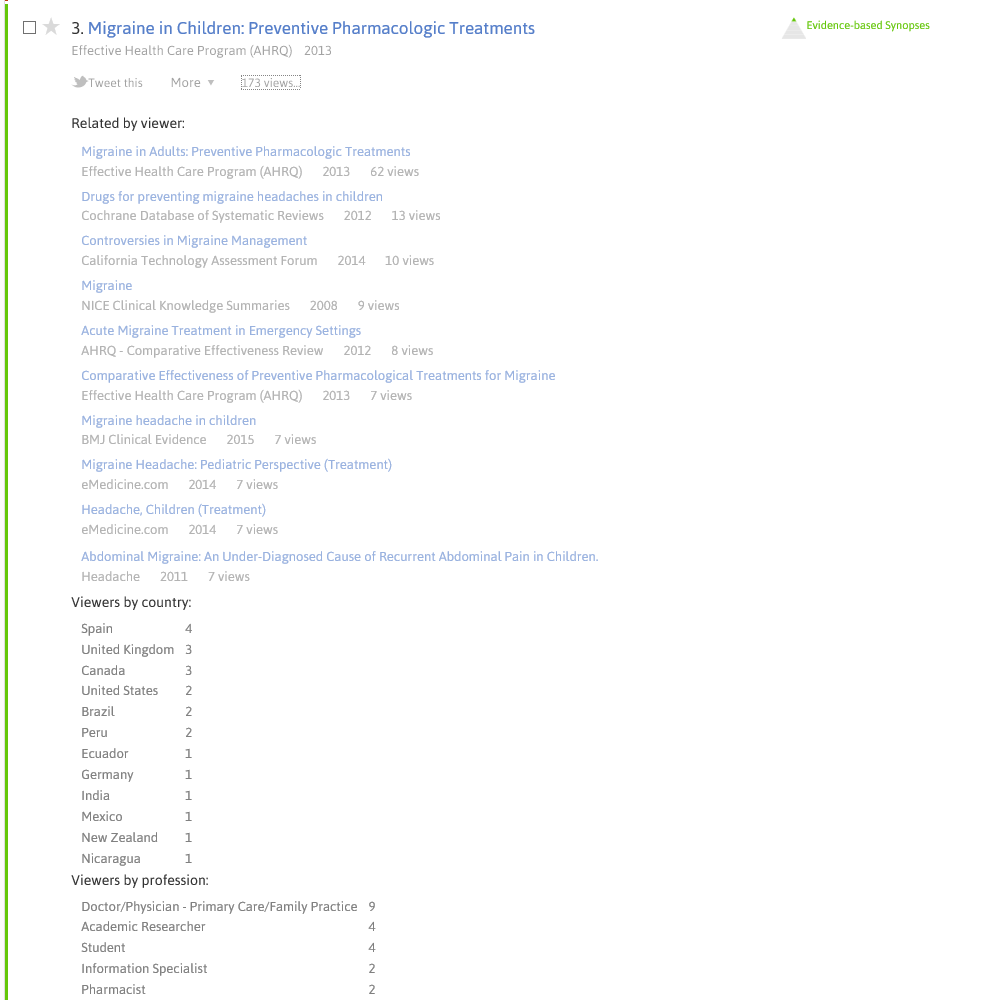
Paper 2: Comparison of conventional pulmonary rehabilitation and high-frequency chest wall oscillation in primary ciliary dyskinesia. Pediatric pulmonology 2014
PubMed
- Comparison of conventional pulmonary rehabilitation and high-frequency chest wall oscillation in primary ciliary dyskinesia. Pediatr Pulmonol. 2014
- Short-term comparative study of high frequency chest wall oscillation and European airway clearance techniques in patients with cystic fibrosis. Thorax. 2010
- Effectiveness of treatment with high-frequency chest wall oscillation in patients with bronchiectasis. BMC Pulm Med. 2013
- A pilot study of the impact of high-frequency chest wall oscillation in chronic obstructive pulmonary disease patients with mucus hypersecretion. Int J Chron Obstruct Pulmon Dis. 2011
- Comparison of high-frequency chest wall oscillation with differing waveforms for airway clearance in cystic fibrosis. Chest. 2007
Trip
- High frequency oscillation in patients with acute lung injury and acute respiratory distress syndrome (ARDS): systematic review and meta-analysis DARE. 2010
- Effect of high-frequency chest wall oscillation on the central and peripheral distribution of aerosolized diethylene triamine penta-acetic acid as compared to standard chest physiotherapy in cystic fibrosis. Chest 2006
- CNE article: pain after lung transplant: high-frequency chest wall oscillation vs chest physiotherapy. American journal of critical care. 2013
- Effect of high-frequency chest wall oscillation versus chest physiotherapy on lung function after lung transplant. Applied nursing research. 2014
Paper 3: Glibenclamide, metformin, and insulin for the treatment of gestational diabetes: a systematic review and meta-analysis. BMJ 2015
PubMed
- Glibenclamide, metformin, and insulin for the treatment of gestational diabetes: a systematic review and meta-analysis. BMJ. 2015
- Metformin vs insulin in the management of gestational diabetes: a systematic review and meta-analysis. Diabetes Res Clin Pract. 2014
- The use of oral hypoglycaemic agents in pregnancy. Diabet Med. 2014
- Screening and diagnosing gestational diabetes mellitus. Evid Rep Technol Assess (Full Rep). 2012
- Benefits and risks of oral diabetes agents compared with insulin in women with gestational diabetes: a systematic review. Obstet Gynecol. 2009
Trip
- Effect comparison of metformin with insulin treatment for gestational diabetes: a meta-analysis based on RCTs. Archives of gynecology and obstetrics. 2014
- The efficacy and safety of DPP4 inhibitors compared to sulfonylureas as add-on therapy to metformin in patients with Type 2 diabetes: A systematic review and meta-analysis. Diabetes research and clinical practice 2015
- Evaluation of the potential for pharmacokinetic and pharmacodynamic interactions between dutogliptin, a novel DPP4 inhibitor, and metformin, in type 2 diabetic patients. Current medical research and opinion 2010
- Metformin vs insulin in the management of gestational diabetes: a meta-analysis. PloS one 2013



Recent Comments