A recurring theme in our recent analyses has been simple but important: if we want to understand evidence-based practice, we should not only ask what evidence exists? We should also ask what clinicians and care professionals are really trying to find out.
AskTrip’s most-viewed Q&A pages offer another window into that question.
These pages may have been reached through AskTrip, the Trip Database, or Google. But that makes the signal more interesting, not less.
The original question tells us what one user wanted to know. Later views show that others recognised the same question as relevant to their own evidence need.
In that sense, page views provide a kind of triangulation. They connect what people ask, what search systems surface, and what users choose to read when looking for evidence.
And the pattern is striking.
The most-viewed AskTrip Q&As are not dominated by narrow treatment questions. They include rehabilitation plans, social inclusion, green spaces, service pathways, monitoring, post-operative care, safeguarding, public health and highly specific clinical scenarios.
This suggests that users are not simply looking for papers. They are looking for help with complex, practical, real-world decisions.
Not just medical lookup
We recently reviewed the top 50 most-viewed AskTrip Q&As. Familiar clinical topics were present: diabetes, COPD, CKD, sinusitis, hepatic steatosis, drug safety and diagnosis.
But sitting alongside these were questions about:
- scar massage in amputee patients
- rehabilitation after ACL injury
- post-intensive care syndrome recovery
- therapeutic gardens in ICU
- nature-based interventions for neurodivergent children
- adults with intellectual disabilities and social inclusion
- child-to-parent violence
- emergency department redirection services
- cultural sensitivity in dietary prescribing
This is not a list dominated by mainstream biomedical topics. It reflects the wider reality of health and care: rehabilitation, therapy, public health, social care, service delivery, inclusion and implementation.
That matters because these are often areas where usual evidence sources may be less satisfying.
Traditional medical evidence tools tend to be strongest for drugs, diagnostics, disease-specific guidelines and formal clinical interventions. They can be less helpful when the question is about recovery, participation, environment, wellbeing, service organisation or community-based care.
So the concentration of views around rehabilitation, green space, social care and disability inclusion may point to an unmet knowledge need. Users may be finding and viewing these answers because they provide something that is harder to get elsewhere: a clear, synthesised, practice-ready account of evidence for complex real-world questions.
This also echoes findings from our earlier analysis, “What clinicians are really trying to find out” That analysis used a different method, looking across the questions being asked rather than the Q&A pages being most viewed. But it pointed in a similar direction.
Many real-world evidence needs sit outside the relative “safety” of simple trial, guideline or drug-effectiveness questions. They involve complex populations, practical decisions, service contexts, rehabilitation, implementation, safety, applicability and judgement.
In that sense, the most-viewed Q&As are not an isolated finding. They reinforce a broader pattern: health and care professionals often come to evidence not just to ask “what works?”, but to understand how evidence applies when the question is messy, multidisciplinary or difficult to answer from usual sources.
Rehabilitation and therapy
One of the strongest themes was rehabilitation, therapy and functional recovery.
Questions covered ACL rehabilitation protocols, post-intensive care syndrome, physical therapy exercise parameters, scar massage in amputees, hypertrophic scar management, and occupational or physiotherapy approaches to specialist neuropsychiatric problems.
These are not abstract evidence questions. They are practical questions.
What does a rehabilitation programme look like?
How often should exercises be done?
What helps recovery, comfort, function or participation?
This is a different knowledge need from simply asking whether a drug works. It requires evidence to be translated into usable guidance.
It also illustrates a wider lesson from AskTrip’s question data: some questions are hard not because evidence is absent, but because the evidence is scattered, indirect, interdisciplinary or difficult to apply.
Green space, children and wellbeing
Another striking cluster involved nature, green space, play and child wellbeing.
Questions included the impact of green spaces on children’s mental health, socioeconomic access to outdoor play, nature-based occupational therapy for neurodivergent children, green care interventions for developmental disorders, and therapeutic gardens in ICU.
These questions sit at the boundary of healthcare, public health, education, environment and wellbeing.
They do not always fit neatly into conventional PICO formats. The intervention may be environmental. The outcomes may include participation, distress, development, wellbeing or quality of life. The evidence may come from different disciplines.
That does not make these questions less important. It makes the evidence need more complex.
Social care, disability and inclusion
A further theme involved adults with intellectual or cognitive disabilities, day-centre activities, art-based interventions, social inclusion, participation and quality of life.
Again, these are not marginal issues. They are central to health and care.
But they are not always well served by conventional clinical evidence pathways. They sit partly outside the traditional model of diagnosis, treatment and disease management.
For AskTrip, this is important. Evidence-based practice does not stop at the clinic door. Many important decisions are about helping people live well, participate, recover, connect and remain safe.
Guideline and safety questions remain central
The broader themes do not replace traditional clinical questions. They sit alongside them.
Many highly viewed Q&As were still about familiar clinical and guideline-focused topics: diabetes in older adults, diabetic foot management, COPD and asthma follow-up, CKD, antibiotic use, gabapentinoid risks and diagnosis of obstructive jaundice.
But even these questions often include real-world modifiers: age, comorbidity, monitoring, adverse effects, diagnostic uncertainty or applicability to a particular setting.
This is the crossover with our previous analyses. The important signal is not just the topic. It is the underlying uncertainty.
Users are often asking:
- Does this evidence apply here?
- Is this safe for this patient group?
- What should I do in practice?
- Is the evidence direct or indirect?
- Is this a research gap, or an application gap?
- Is the problem that evidence is missing, or that existing evidence is hard to use?
That is what clinicians and care professionals are really trying to find out.
Evidence demand, not just evidence supply
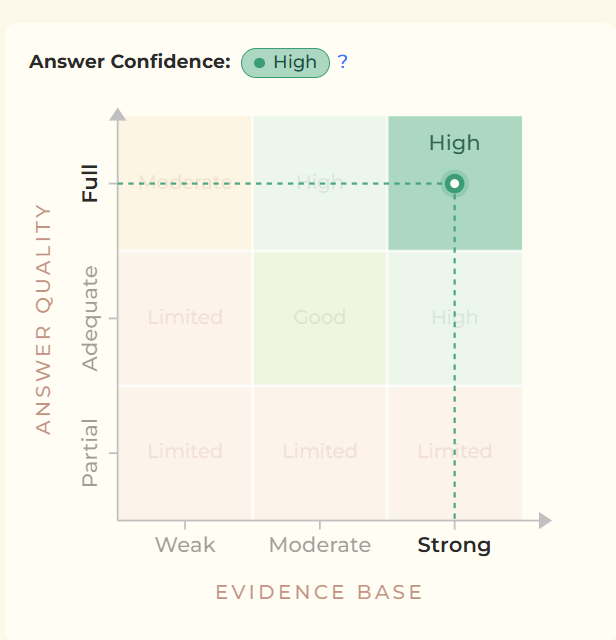
The most-viewed Q&As were not dominated by weak or speculative topics. Most had evidence ratings of Moderate or High, with only a small number rated Limited.
That is encouraging. It suggests that many practical, multidisciplinary questions can be answered using reasonably strong evidence.
But the value of AskTrip is not just in finding evidence. It is in making evidence usable.
For some questions, the key task is to identify direct evidence. For others, it is to say clearly that the evidence is indirect, incomplete or difficult to apply. For many, the challenge is translation: turning scattered evidence into a clear account of what it means for practice.
That is why these viewed Q&As are useful signals. They help reveal the demand side of evidence-based medicine: the questions, uncertainties and practical decisions that bring people to evidence in the first place.
Evidence for the real world
AskTrip’s most-viewed Q&As suggest that real-world evidence needs are broader and messier than conventional evidence systems often assume.
They cross boundaries between medicine, rehabilitation, psychology, public health, social care and service design.
They also suggest that some of the strongest unmet needs may sit outside the most mainstream medical topics – in areas where professionals still need evidence, but where usual sources may not provide clear, practice-ready answers.
Evidence-based medicine will always need to ask: what evidence exists?
But AskTrip’s question data keeps pointing us back to another question:
What are clinicians and care professionals really trying to find out?
That is the challenge – and the opportunity – for AskTrip: to make evidence usable not only for clinical decisions, but for the wider decisions that shape care, recovery, inclusion and wellbeing.




Recent Comments