Shops, they connect the producer to the consumer.
A supermarket contains a large number of products from a large number of producers. Consumers come in and wander round picking off products off the shelves. Problems arise in a number of ways, and one clear example is when a user can’t find the product. The shopper’s need is unmet. The shopper is dissatisfied.
In many ways Trip is a supermarket – a supermarket of evidence. Consumers come to the site with a wide variety of needs and we do our best to match the consumer with the producer. The consumers being doctors, nurses etc. The producers are the likes of NICE, AHRQ, Cochrane, BMJ etc.
Problems arise in a number of ways, and one clear example is when a user can’t find the evidence. The health professional’s need is unmet. The health professional is dissatisfied.
I can’t help feeling the likes of Tesco, Carrefour, Spar, Walmart etc really understand their consumers and try to understand their unmet needs/frustrations. A few years ago a celebrity chef/cook mentioned a product (some sort of birds egg) which caused a huge increase in interest and large unmet need at the supermarkets. Supermarkets realised they were missing market and desperately sought appropriate stock.
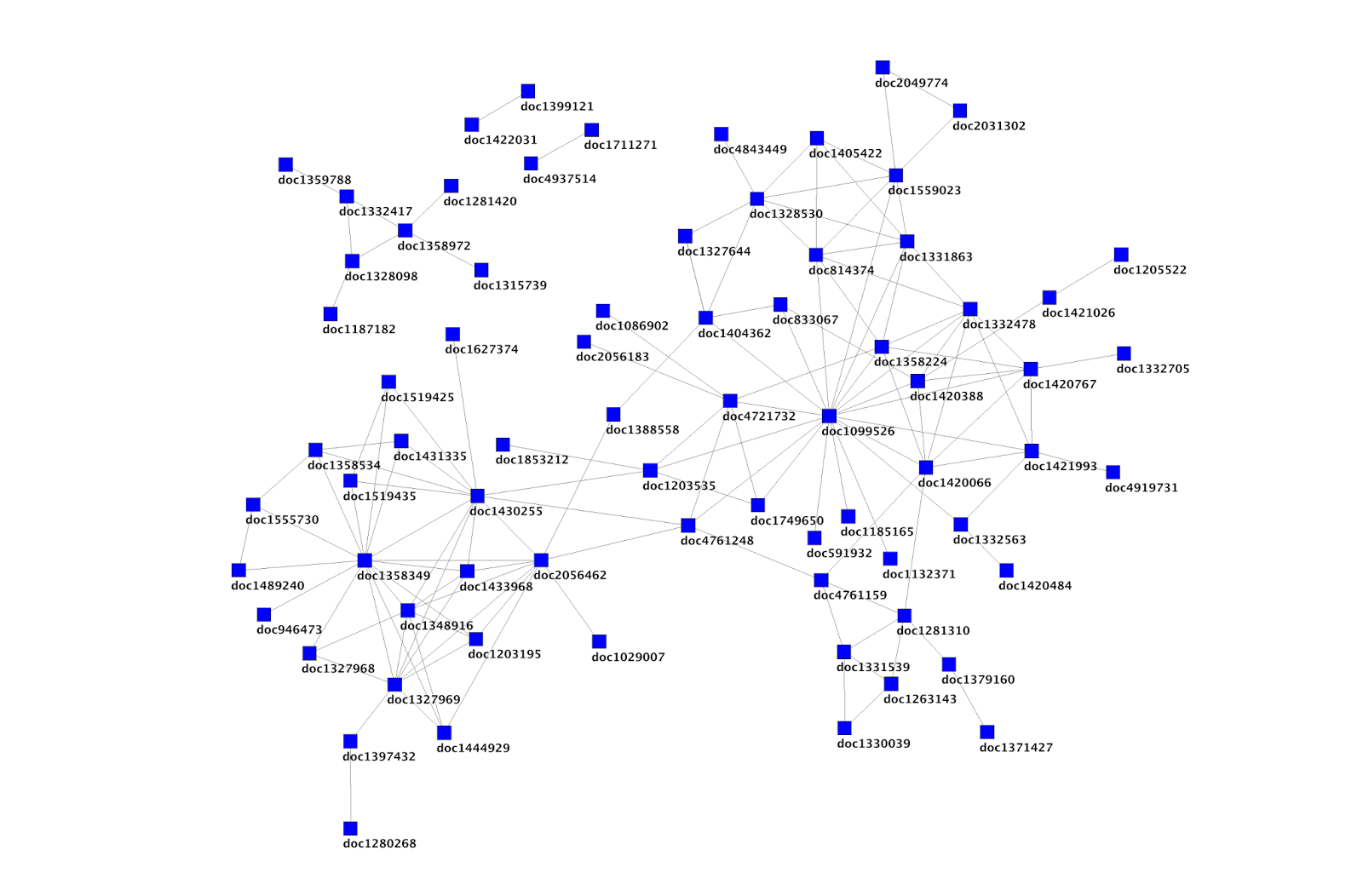
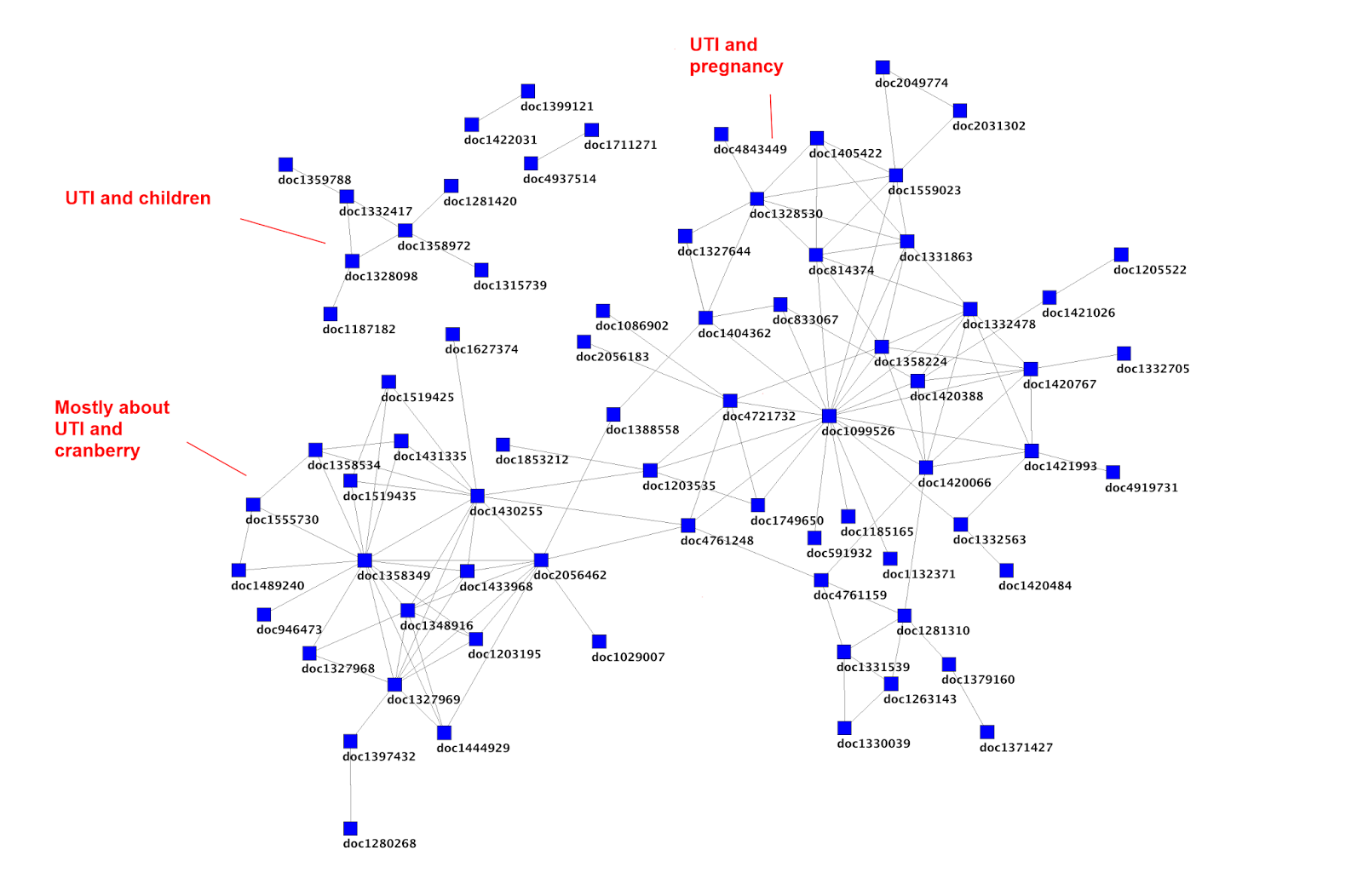
In Trip, we record most things a user does on the site. It allows us to better understand the research landscape and draw information (and pretty) graphs such as seen here. One thing we’re not good at is mining the data on dissatisfied users. As ever time is a problem – there’s only one of me! But I don’t think I’ve ever given it a great deal of thought.
Arguably a user coming to the site and searching and not clicking on an article is a clear sign that they have not had their information need met. I wonder if it’s more sophisticated than that. It might be that on average – for each search – 2 articles are clicked on. Can we spot trends where for a given search term(s) lower than average articles are clicked on?
This could have two effects:
- Trip could try and locate producers of evidence in this area and bolster our index.
- It might be that evidence has not been produced at all and therefore the challenge is down to the producers to help meet this un-met need.
Just a thought.

Recent Comments