Relevancy is a key element of search. A user types a term and the intention it to retrieve a document related to the term(s) used. But relevancy is relative and in the eye of the beholder. If someone searches for measles and the document has measles in the title, then it’s clear it’s relevant. But there might be another document, about infectious diseases, which has a chapter on measles. The document is 10,000 words long and has 50 mentions of measles = 0.5%. So, that seems a reasonable matche.
But what about a 100,000 word document, entitled prostate cancer, which mentions measles once = 0.001%. The document is a true match – as in it mentions the search term – but the reality is it’s clearly not about measles. Another example from a recent presentation I gave:
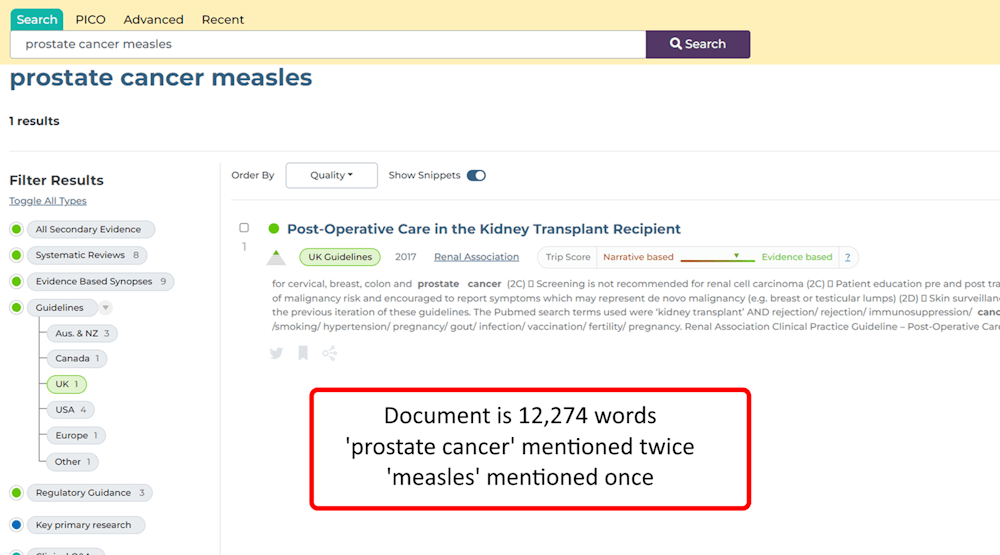
It’s a contrived example, but helps illustrate the issue!
For most searches this isn’t really a big deal as most of the time the top results will always be relevant. If the search returns 50 pages of results the low relevancy results will appear towards the end of the search – say from page 40. Not many people go to that results page – so it’s not an issue.
However, it is an issue when you have few results – either a very specific search OR if you click on a filter (eg UK guidelines) – then if 75% of the results are relevant and 25% poor – you can see some fairly poor results even on the first page. True hits as they contain the search terms but not really relevant to the user’s intention!
So, we’re exploring multiple options to help for instance An alternative search button? But another approach is to summarise long documents into shorter ones – so removing very low frequency words. We’ve experimented with ChatGPT and that summarised too much, so the search went from too sensitive to too specific. So, another approach is to do text analysis to explore word frequency (how often a word appears in a document) and remove those terms that are rarely mentioned (perhaps remove those terms only mentioned 1-3 times (depending on the document length.
We took one NICE guideline and analysed the frequency of words across the document and it looks like this:
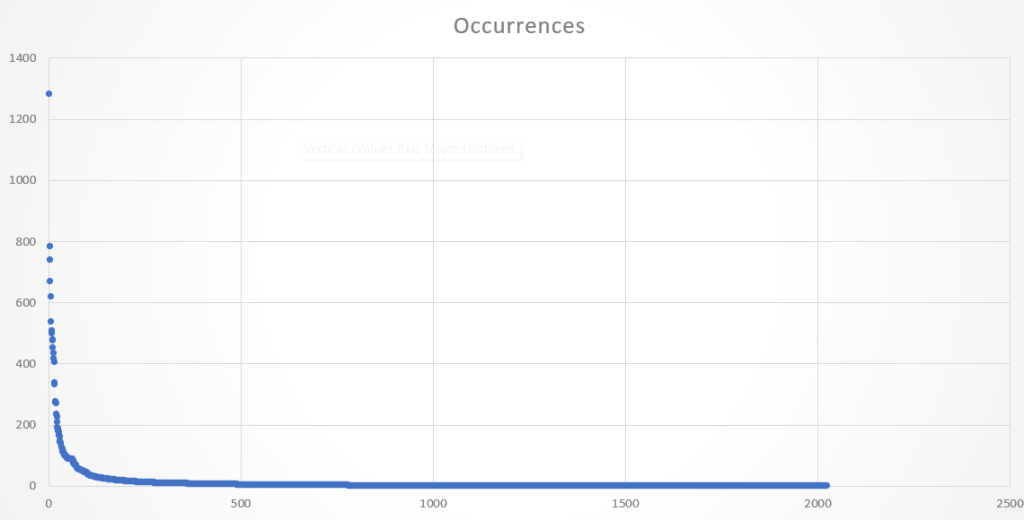
The Y-axis denotes the number of times words appear in the document. With more granularity:
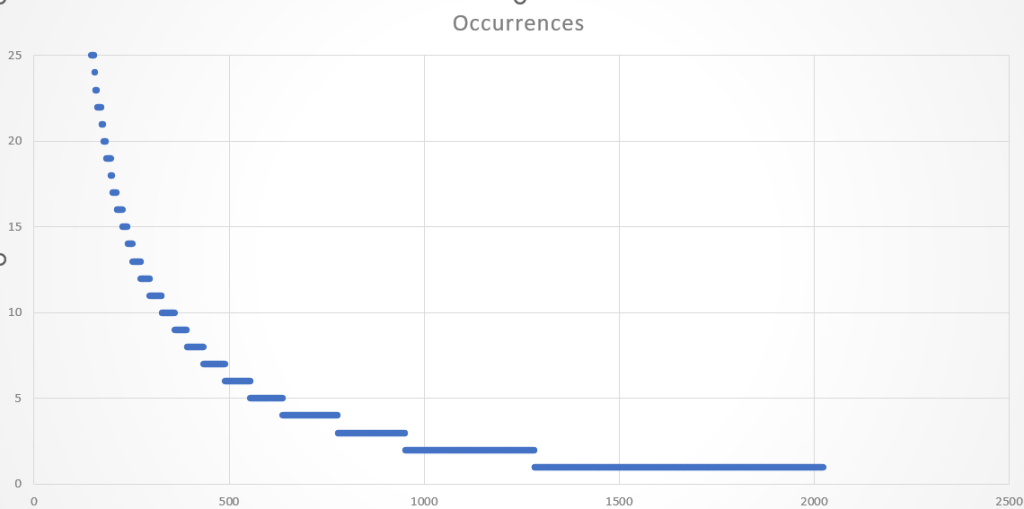
So, we’re going to run some tests where we remove terms mentioned 1 time, 2 times or 3 times (so, three separate tests). These don’t remove many terms but will hopefully remove the terms that cause problematic sensitivity. In the search example above, removing terms that appear once, would remove the term measles, while removing terms that are mentioned twice will remove prostate cancer.
This issue has been frustrating me for years so hopefully we’re edging closer to solving it!

3 Pingback