As mentioned in the previous post we have been spending a lot of effort trying to improve our search and the current focus (possibly obsession) is removing low relevancy results from the search.
TLDR long documents might mention the search term only once, in say 50,000 words. In that situation it’s almost an incidental result – but it’s still a true hit as it contains the user’s search terms even though it’s irrelevant to the user’s intention. One approach we have tried is to create a pseudo-abstract of guidelines – typically long documents – to see how that fared (by removing terms not linked to the core themes of the guideline). And here’s an example search taken from our testing site:
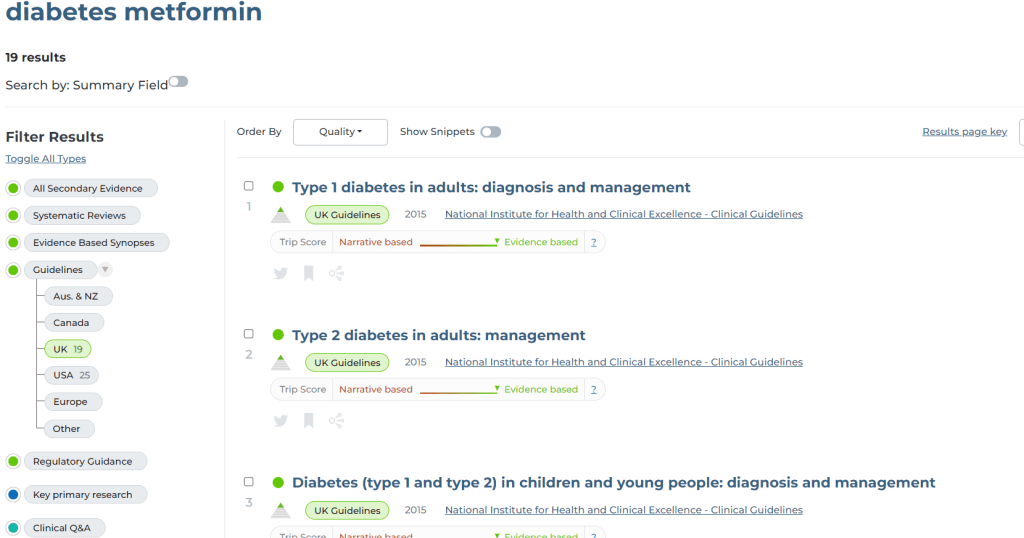
This image shows a search for diabetes and metformin and it returns 19 UK guidelines and the top results all look good. However, one was Guidelines for the investigation of chronic diarrhoea in adults. This contains the word metformin 1 time and diabetes 8 times in a 21 page document. So, another example of a result that is a poor match! This next image is when we searched just the ChatGPT summary:
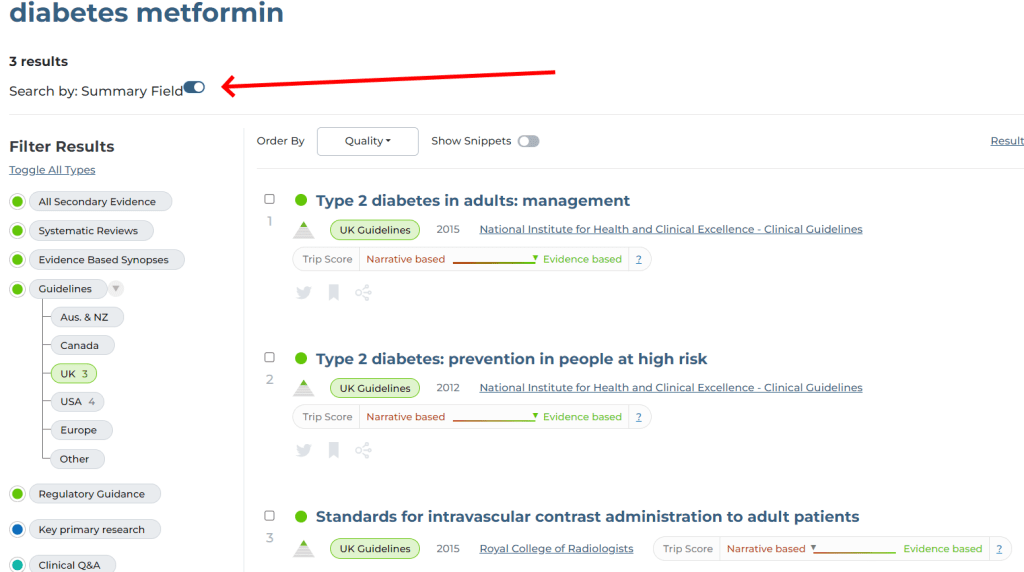
3 results, so removing 16 results, including Guidelines for the investigation of chronic diarrhoea in adults. So, that’s good. However, it also removed Diabetes (type 1 and type 2) in children and young people: diagnosis and management, from NICE. In this 91 page document it mentions metformin 28 times. It is entirely feasible that a user, searching for diabetes and metformin, might think the NICE document was relevant!
Bottom line: Using the ChatGPT summary, as we have, means the search is too specific. So, on to the next approach….

Leave a comment