Yesterday, I returned to my former workplace – Public Health Wales (PHW) – to meet with the evidence team and discuss Trip’s use of large language models (LLMs). It was a great meeting, but unexpectedly challenging – in a constructive way. The discussion highlighted our differing approaches:
- Automated Q&A – focused on delivering quick, accessible answers to support health professionals.
- PHW evidence reviews – aimed at producing more measured, rigorous outputs, typically developed over several months.
The conversation reminded me of when I first began manually answering clinical questions for health professionals. Back then, I worried about not conducting full systematic reviews – was that a problem? Over time, I came to realise that while our responses weren’t systematic reviews, they were often more useful and timely than what most health professionals could access or create on their own. Further down the line, after many questions, I theorised that evidence accumulation and ‘correctness’ probably looked like this:
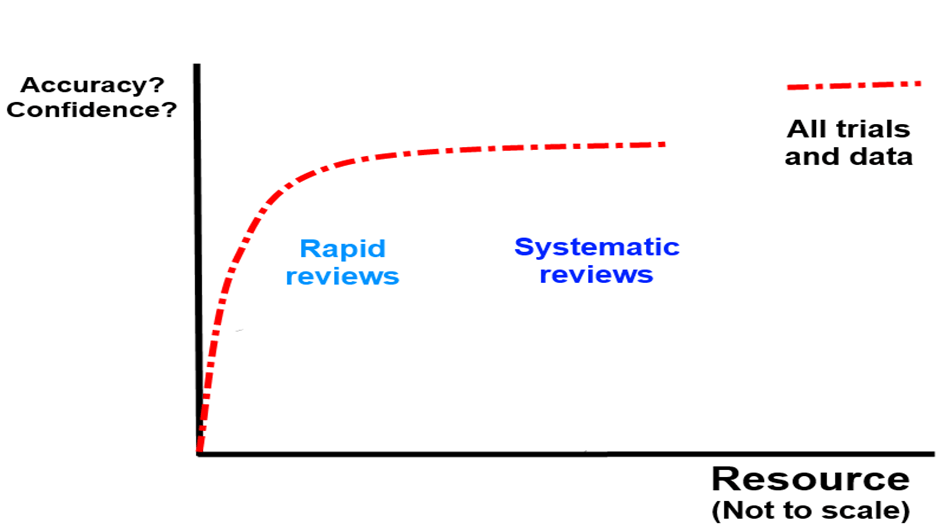
In other words you can – in most cases – get the right answer quite quickly and then after that it becomes a law of diminishing returns… In the graph above I would include Q&A in the ‘rapid review’ space.
Back at PHW, their strong reputation – and professionalism – means they’re understandably cautious about producing anything that could be seen as unreliable. Two key themes emerged in our discussion: transparency and reproducibility. Both are tied to concerns about the ‘black box’ nature of large language models: while you can see the input and the output, what happens in between isn’t always clear.
With their insights and suggestions, I’ve started sketching out a plan to address these concerns:
- Transparency ‘button’ – While this may not be included in the initial open beta, the idea is to let users see what steps the system has taken. This could include the search terms used and which documents were excluded (from the top 100+ retrieved).
- Peer review – Our medical director will regularly review a sample of questions and responses for quality assurance.
- Encourage feedback – The system will allow users to flag responses they believe are problematic.
- Reference check – We’ll take a sample of questions, ask them three separate times, and compare the clinical bottom lines and the references used.
This last point ties directly to the reproducibility challenge. We already know that LLMs can generate different answers to the same question depending on how and when they’re asked. The key questions are: How much do the references and answers vary? And more importantly, does that variation meaningfully affect the final clinical recommendation? That might make a nice research study!
If you have any additional suggestions for strengthening the Q&A system’s quality, I’d love to hear them.
Two final reflections:
- First, it was incredibly valuable to gain an external perspective on our Q&A system and to better understand their scepticism and viewpoint (thank you PHW).
- Second, AI is advancing rapidly, and evidence producers – regardless of their focus – need to engage with it now and start planning for meaningful integration.

Leave a comment