Rocio has been a wonderful supporter of Trip for years, and when she offered to test our Q&A system, she brought her usual diligence to the task. After trying it out, she emailed to ask why a key paper – a recent systematic review from a Lancet journal – wasn’t included in the answer. That simple question kicked off a deep dive, a lot of analysis, and a lot of work… and ultimately led to the realisation that we’ve now built a much better product.
At first, we thought it was a synonyms issue. The question used the term ablation, but the paper only mentioned ablative in the abstract. Simple enough – we added a synonym pair. But the issue persisted. So… what was going on? Honestly, we had no idea.
What it did make us realise, though, was that we’d made a whole bunch of assumptions – about the process, the steps, and what was actually happening under the hood. So, the big question: how do we fix that?
The underlying issue was our lack of visibility into what was happening under the hood. To truly understand the problem, we needed to build a test bed – something that would reveal what was going on at every stage of the process. This included:
- The transformation of the question into search terms
- The actual search results return
- The scoring of each of the results
- The final selection of articles to be included
The test bed looks like this and, while not pretty, it is very functional:
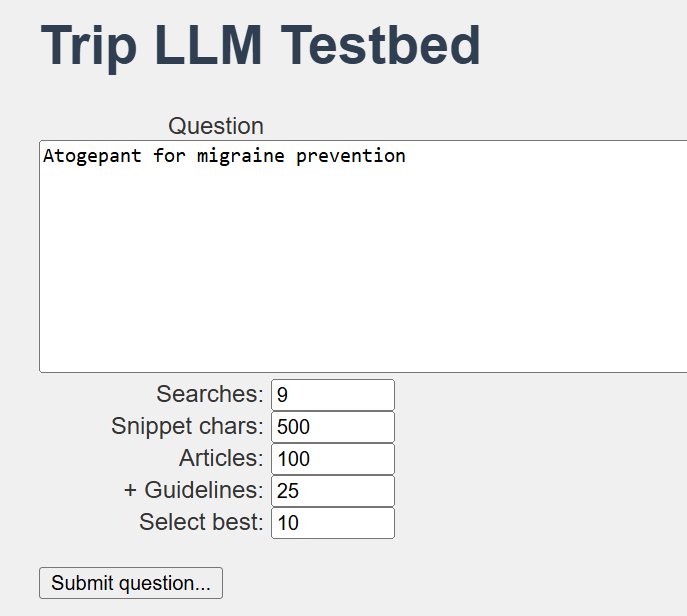
We were able to tweak and test a lot of variables, which gave us confidence in understanding what was really happening. So, what did we discover (and fix)?
- Partial scoring by the LLM: While up to 125 results might be returned, the AI wasn’t scoring all of them – only about two-thirds. That’s why the Lancet paper was missing.
Fix: We improved the prompt to ensure the LLM evaluated all documents. - Over-reliance on titles: When we only used titles (without snippets), we often missed key papers – especially when the title was ambiguous.
Fix: We added short snippets, which solved the issue and improved relevance detection. - Arbitrary final selection: If more than 10 relevant articles were found, the AI randomly selected which ones to include in the answer.
Fix: We built a heuristic to prioritise the most recent and evidence-based content. This single change has significantly improved the robustness of our answers – and testers already thought the answers were great!
So, we’ve gone from a great product – built on a lot of assumptions – to an even greater one, now grounded in solid foundations that we can confidently stand behind and promote when it launches in early June.
And it’s all thanks to Rocio. 🙂

1 Pingback