We have just pushed out the revamped Advanced Search onto our test site:
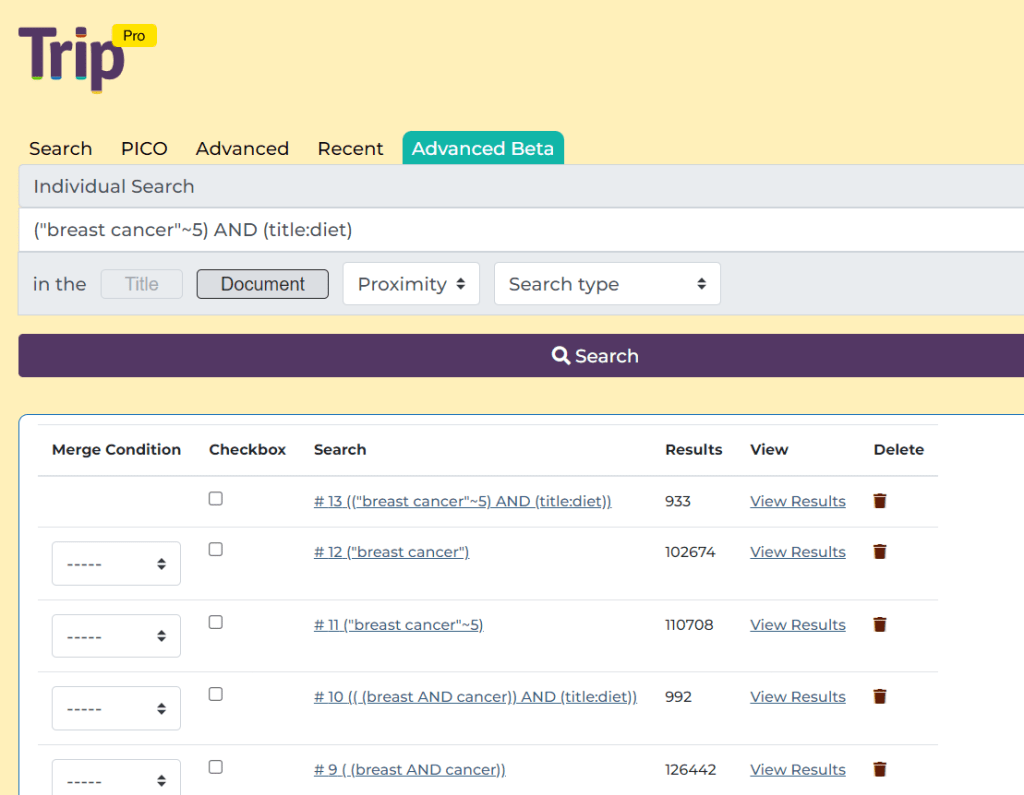
We’re testing it in-house but are keen to get some external users to test it. So, if you are interested please contact me via jon.brassey@tripdatabase.com.
We have just pushed out the revamped Advanced Search onto our test site:
We’re testing it in-house but are keen to get some external users to test it. So, if you are interested please contact me via jon.brassey@tripdatabase.com.
As mentioned in the previous post we have been spending a lot of effort trying to improve our search and the current focus (possibly obsession) is removing low relevancy results from the search.
TLDR long documents might mention the search term only once, in say 50,000 words. In that situation it’s almost an incidental result – but it’s still a true hit as it contains the user’s search terms even though it’s irrelevant to the user’s intention. One approach we have tried is to create a pseudo-abstract of guidelines – typically long documents – to see how that fared (by removing terms not linked to the core themes of the guideline). And here’s an example search taken from our testing site:
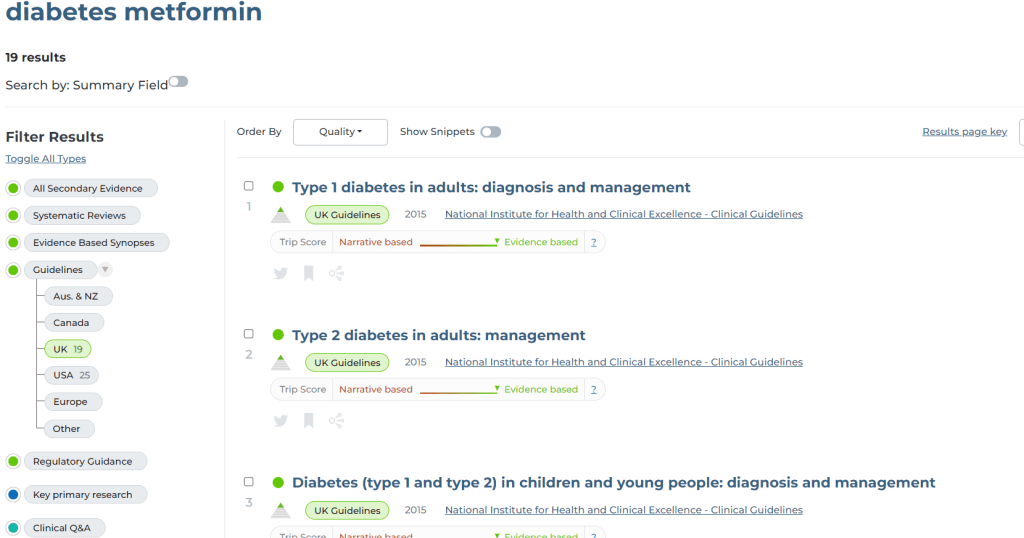
This image shows a search for diabetes and metformin and it returns 19 UK guidelines and the top results all look good. However, one was Guidelines for the investigation of chronic diarrhoea in adults. This contains the word metformin 1 time and diabetes 8 times in a 21 page document. So, another example of a result that is a poor match! This next image is when we searched just the ChatGPT summary:
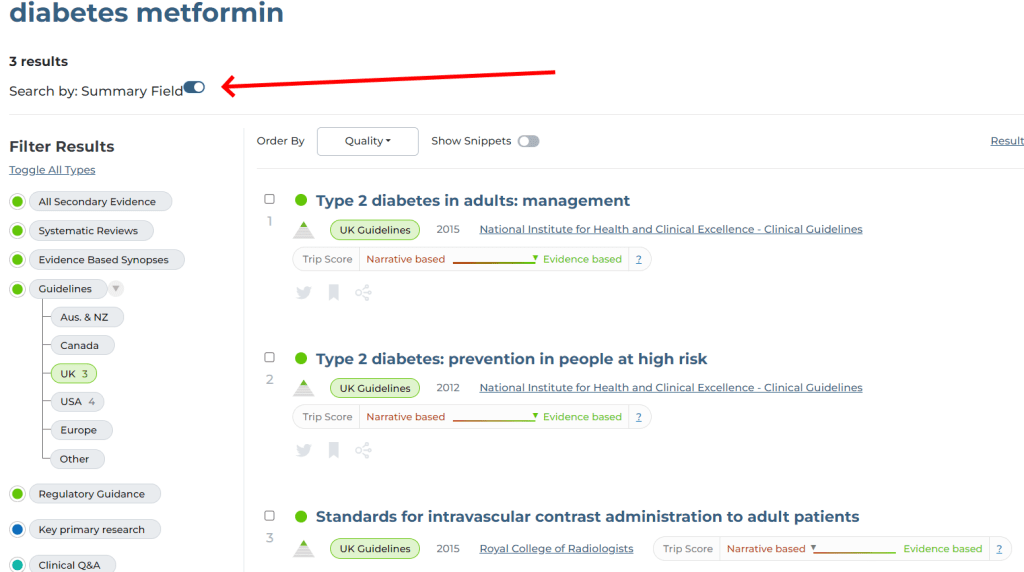
3 results, so removing 16 results, including Guidelines for the investigation of chronic diarrhoea in adults. So, that’s good. However, it also removed Diabetes (type 1 and type 2) in children and young people: diagnosis and management, from NICE. In this 91 page document it mentions metformin 28 times. It is entirely feasible that a user, searching for diabetes and metformin, might think the NICE document was relevant!
Bottom line: Using the ChatGPT summary, as we have, means the search is too specific. So, on to the next approach….
Relevancy is a key element of search. A user types a term and the intention it to retrieve a document related to the term(s) used. But relevancy is relative and in the eye of the beholder. If someone searches for measles and the document has measles in the title, then it’s clear it’s relevant. But there might be another document, about infectious diseases, which has a chapter on measles. The document is 10,000 words long and has 50 mentions of measles = 0.5%. So, that seems a reasonable matche.
But what about a 100,000 word document, entitled prostate cancer, which mentions measles once = 0.001%. The document is a true match – as in it mentions the search term – but the reality is it’s clearly not about measles. Another example from a recent presentation I gave:
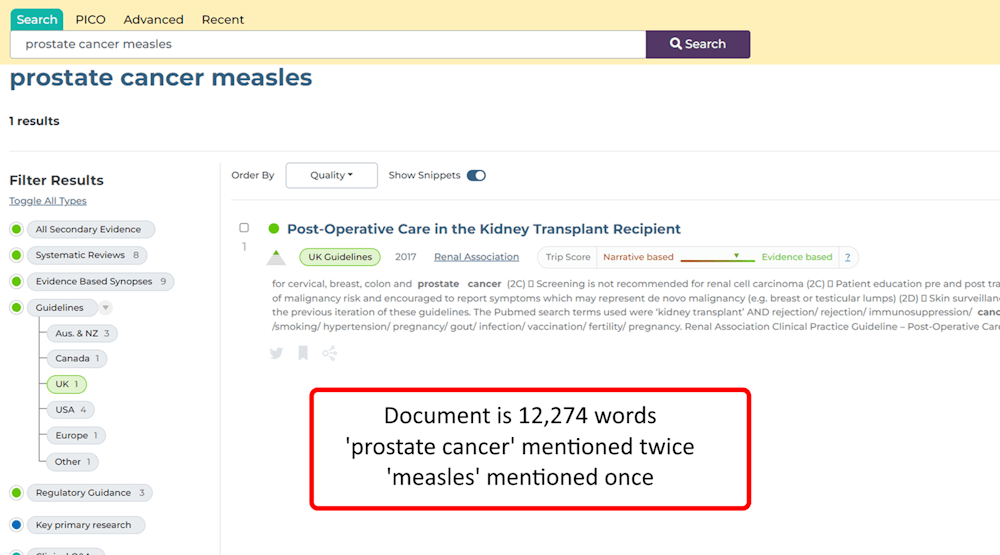
It’s a contrived example, but helps illustrate the issue!
For most searches this isn’t really a big deal as most of the time the top results will always be relevant. If the search returns 50 pages of results the low relevancy results will appear towards the end of the search – say from page 40. Not many people go to that results page – so it’s not an issue.
However, it is an issue when you have few results – either a very specific search OR if you click on a filter (eg UK guidelines) – then if 75% of the results are relevant and 25% poor – you can see some fairly poor results even on the first page. True hits as they contain the search terms but not really relevant to the user’s intention!
So, we’re exploring multiple options to help for instance An alternative search button? But another approach is to summarise long documents into shorter ones – so removing very low frequency words. We’ve experimented with ChatGPT and that summarised too much, so the search went from too sensitive to too specific. So, another approach is to do text analysis to explore word frequency (how often a word appears in a document) and remove those terms that are rarely mentioned (perhaps remove those terms only mentioned 1-3 times (depending on the document length.
We took one NICE guideline and analysed the frequency of words across the document and it looks like this:
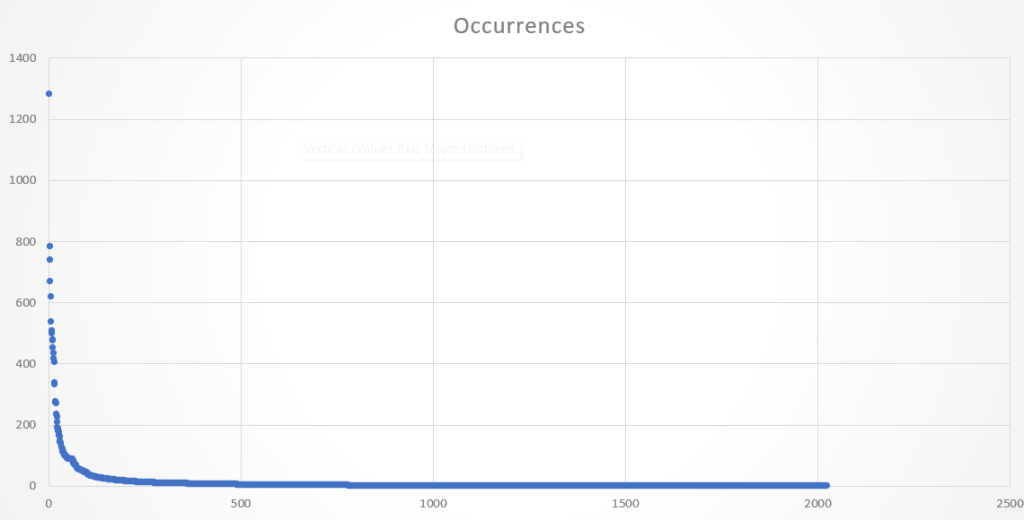
The Y-axis denotes the number of times words appear in the document. With more granularity:
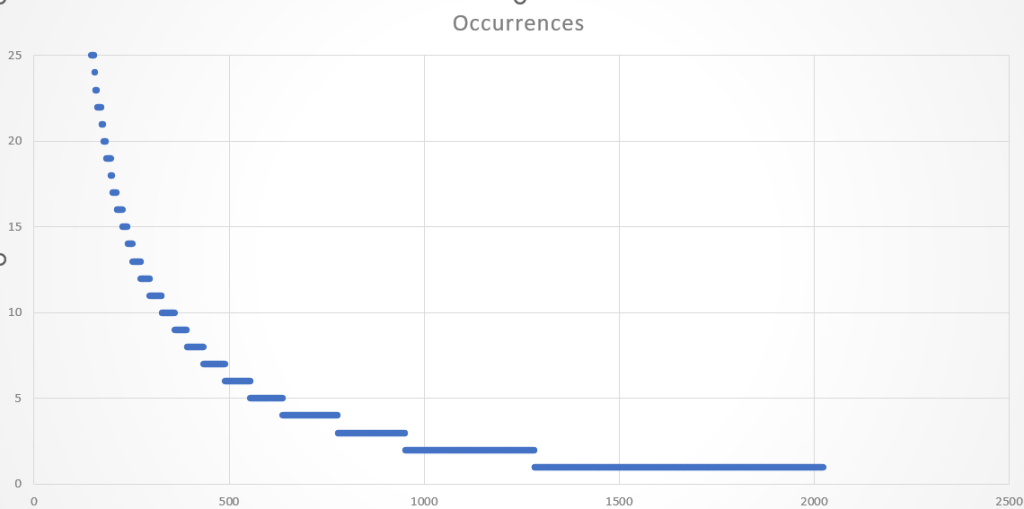
So, we’re going to run some tests where we remove terms mentioned 1 time, 2 times or 3 times (so, three separate tests). These don’t remove many terms but will hopefully remove the terms that cause problematic sensitivity. In the search example above, removing terms that appear once, would remove the term measles, while removing terms that are mentioned twice will remove prostate cancer.
This issue has been frustrating me for years so hopefully we’re edging closer to solving it!
After a user asked the Q about the differences I gave my answer – in a nutshell it’s quality over quantity. But then I thought, why not ask ChatGPT? The answer is below and it’s pretty good (but not perfect), a few observations:
Anyway, the answer it provided is below:
The Trip Database and PubMed are both search engines for retrieving biomedical and clinical literature, but they have some key differences in terms of scope, focus, user interface, and types of content they index. Here are some of the differences:
Both platforms have their own unique strengths and weaknesses, and the choice between the two may depend on your specific needs.
Our current advanced search has been static for years and since then other advanced search systems have evolved and people have become comfortable with these newer approaches. Bottom line: our existing advanced search is a bit clunky! So we have prioritised work on this and here is the first look:
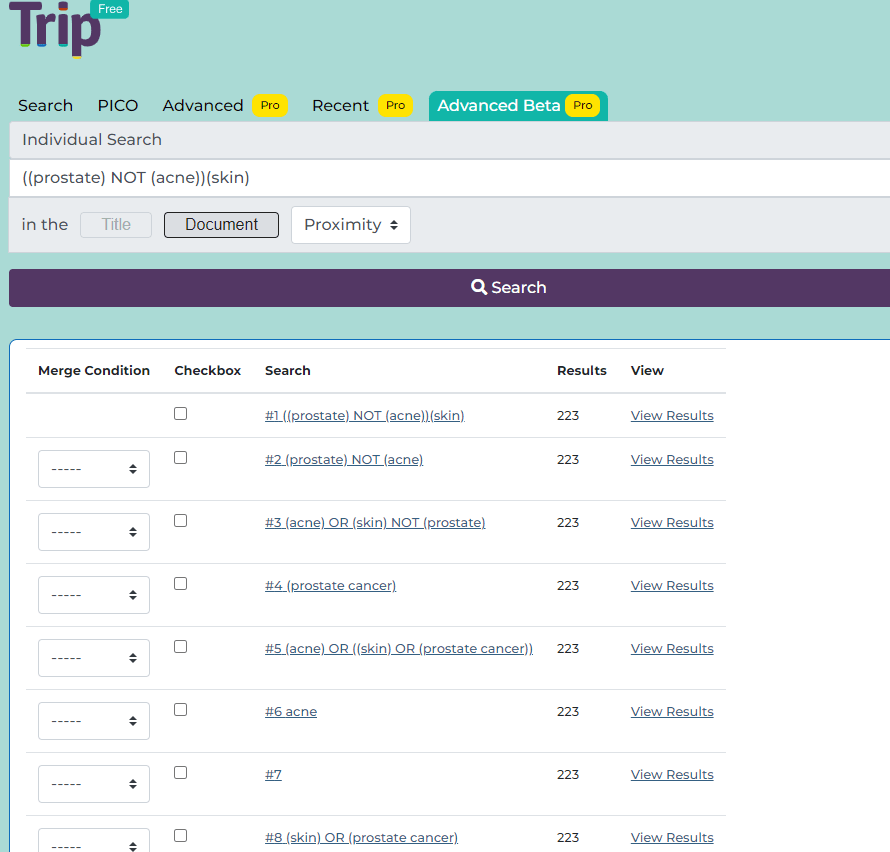
As mentioned early days, but you can see the direction we’re taking. I’d like to think we can have the proper version released in the next 2 months.
I’ve been preparing a talk for ESSIR and it’s been great thinking through some information retrieval problems to talk about. Two of the are linked to quality and not quantity of evidence. If you do a search and find 1000 results, most people will find that 950 too many… So, it’s important that the top results are the best. Our algorithm attempts to do it and it does it pretty well, but it could be better.
I found myself looking at the search for prostate cancer screening which generated over 12,000 results. Of the top ten, 6 are ‘evidence based’ (ie the top green layer) while 4 are journal articles (these get boosted as they’re published in the last two years). This struck me as a bit odd as we emphasise the secondary evidence side of things… So, what if we did things differently:
In the above examples the search is very specific, removes the lower quality evidence and the user loses seeing some potential journal articles – which they can navigate to if they wish.
For information specialists – who typically want all results – we could allow that. But for busy clinicians we could allow some way of only returning a fraction of the results with a focus on higher quality evidence.
Discuss!
Amazingly, in around a fortnight, we have created a rudimentary ACQA system and the initial results are both good and bad! We’ve run through a number of questions and some have been pretty good and others pretty bad. An example of a good ACQA was Is brexpiprazole effective in schizophrenia? with our system generating the following answer:
“Brexpiprazole has shown effectiveness in treating schizophrenia based on a post hoc analysis of various short- and long-term studies. These studies demonstrated that brexpiprazole led to clinically relevant improvements in functioning for patients with schizophrenia in both short and long durations. Patients on brexpiprazole experienced greater improvements in Personal and Social Performance (PSP) scores and all PSP domains compared to those on placebo. The Global Assessment of Functioning (GAF) scale also indicated better functional remission for brexpiprazole-treated patients. These improvements were noticeable during the treatment of acute schizophrenia and generally persisted over a one-year period. However, low-dose brexpiprazole might not be as effective as standard-dose brexpiprazole in improving efficacy and safety for acute schizophrenia, potentially carrying a risk of weight gain. Additionally, a study highlighted that brexpiprazole treatment reduced impulsive behavior and associated brain activation in patients with schizophrenia. Overall, brexpiprazole appears to be effective in managing symptoms and improving functioning in schizophrenia.“
I’m not saying it’s perfect but pretty good for a first attempt. This answer was all referenced and mostly created from secondary evidence. However, a worse answer was generated for Is zolmitriptan effective in migraines?, which generated this answer:
“Zolmitriptan, a medication commonly used for migraines, belongs to the triptan class of drugs. It works by constricting blood vessels in the brain and reducing inflammation. Studies have shown its effectiveness in relieving migraine symptoms such as headache, nausea, and sensitivity to light and sound. It can provide relief within two hours of taking it. However, its effectiveness may vary and it may have side effects. Consultation with a healthcare professional is important. The provided text does not directly address the effectiveness of zolmitriptan in migraines.“
But understanding the process and why some answers are so poor have given us a load of learning, some easy to respond to but others less so. Currently, the biggest struggle is transforming the question into appropriate search terms. We’ll continue to use LLMs to try to solve this but an easier route might be to include the users more and make it semi-automatic. In many way I favour this, it gives users more understanding of the process and it’s less ‘black box’. It might add an extra step but the extra reassurance might be worth it.
Early days and all to play for!
We started the Trip Database due to our work answering clinical questions. Trip has now been running for over 25 years and we’ve never strayed far from clinical question answering. So, it is really pleasing to say that we’ve just started work on an automated Q&A system. More precisely, users can ask a free-text question and we’ll deliver an answer.
In our internal testing the system worked amazingly well, including on the questions deemed clinically difficult. We were able to expose the references used, so indicating the likely robustness of the answer. Our internal testing was done manually, but all the steps can be automated – now we know the process works. So, we now automate it to generate a very basic testing system. When we get there, we’ll ask users to test it and we go from there.
Coupling clinical Q&A with our hierarchy of evidence is really exciting!
Hundreds of response meant it was more time-consuming to analyse but here are the headlines:
Profession of respondents
Reasons for using Trip
Any suggestions for new sites to add
The top 5 suggestions being:
Suggested improvements
There were very few that got more than one mention:
Is there anything else you would like to share about your experience on Trip?
What was nice to see was overwhelmingly positive comments (including my favourite: “Go further, please, you are unique!“), but a few constructive comments and some negatives:

Recent Comments