2023 was a great year for Trip.
We continue to have a impressive impact on care around the globe, helping support millions of decisions with evidence-based content. This is Trip’s core function, as such, it’s ‘business as usual’. However, we have continued to improve the site as much as we can and 2023 was full of significant improvements.
First quarter of 2023: A real focus on quality improvement including the way we handle updates to content such as systematic reviews and ongoing clinical trials. We also started work on a major de-duplication effort and ending the quarter by refining our aspirations on quality.
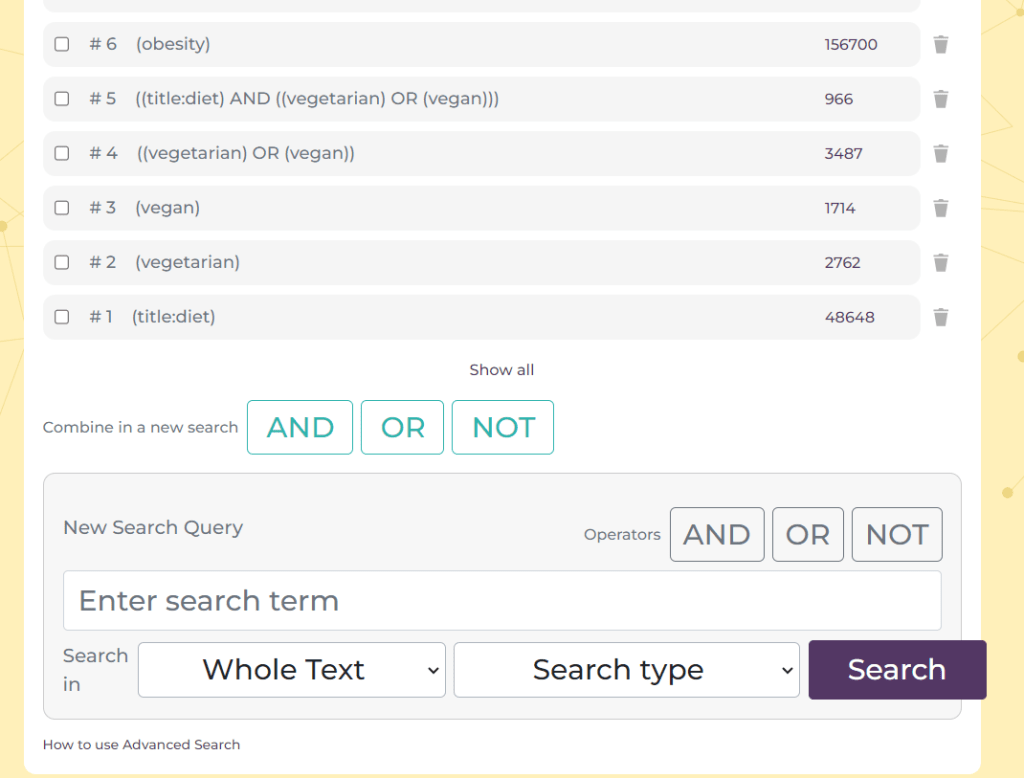
Second quarter of 2023: This is where we really started to explore the potential of large language models (LLMs) such as ChatGPT. We also introduced scoring systems for guidelines and RCTs and a new guideline category for Europe. Finally, our de-duplication efforts saw 143,218 duplicate articles removed from Trip.
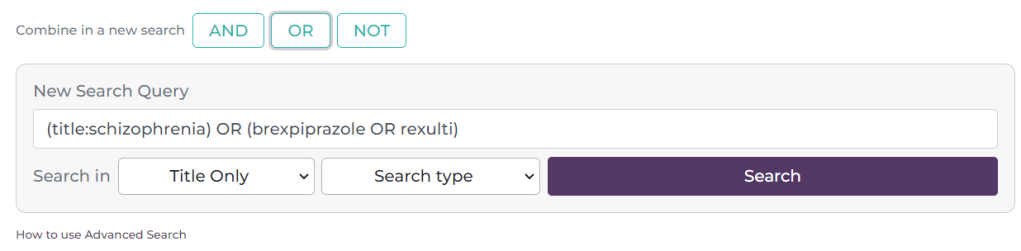
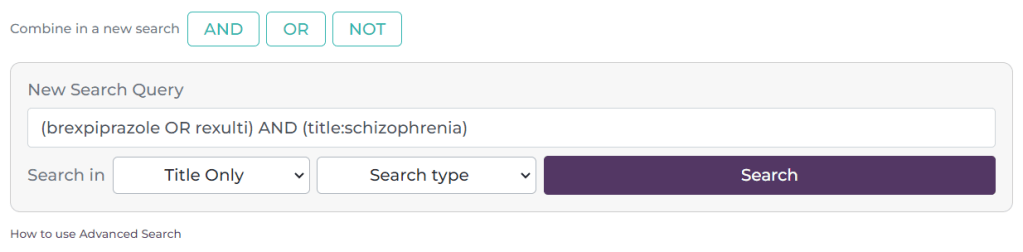
Third quarter of 2023: Our user survey results were published which is always interesting for us. We started exploring automated clinical Q&A using LLMs (see here and here). We also started our overhaul of the advanced search and started exploring some improvements to search relevancy.
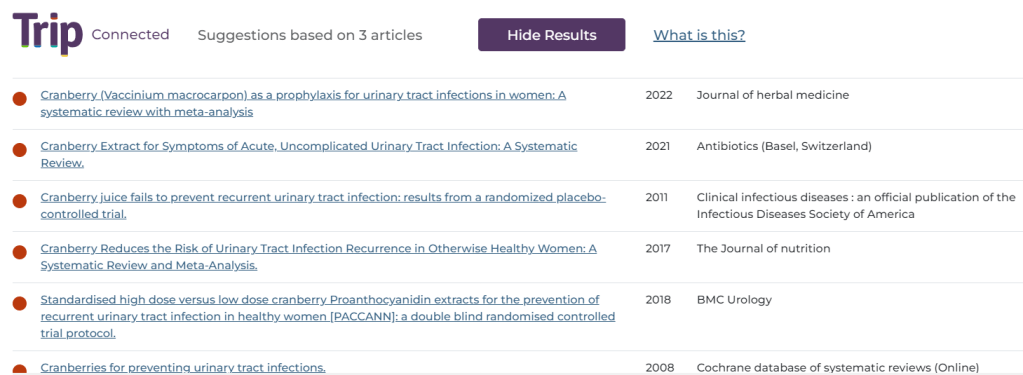
Fourth quarter of 2023: We finished the year off strongly with the release on the new advanced search and the wonderful connected articles. We continued to push ahead with our LLM work with two main projects occupying our time (as well as a bunch of ideas bubbling away in the background). The two projects being a fully automated evidence review system and a clinical Q&A system. We also announced the creation of the AI Innovation Circle to help us to manage the AI potential/hype. Finally, we announced the main focus for the start of 2024: moving the Trip infrastructure to ‘the cloud’ and, unsurprisingly AI!
All this remarkable progress is supported by having a stable business model that has allowed us to remain independent and grow (as the site improves our income increases; a virtuous cycle)! While subscriptions to Trip Pro is the main source of income our bespoke rapid reviews have boomed in 2023. These are produced for a small group of selected organisations who appreciate our speed, evidence-based approach and cost-effectiveness. If you want to know more please email us.
Oh yes, don’t forget, we are still a ridiculously small organisation.
Another great boost for us is our users, they are wonderful and frequently crucial in helping us with surveys, feedback on new features etc. So, a big thank you from Trip to you.
2023 has proved immense, 2024 will hopefully be even bigger.





Recent Comments