Inspired by the work of Google (see our post A great example of the power of vector search), we’ve developed a test system based on a subset of Trip documents covering GLP-1 receptor agonists. Rather than relying on a single search method, the system effectively runs two searches at the same time – one keyword-based and one vector-based – and combines what each finds.
Here’s an illustration based on a search for “GLP-1 and neurological disorders”:
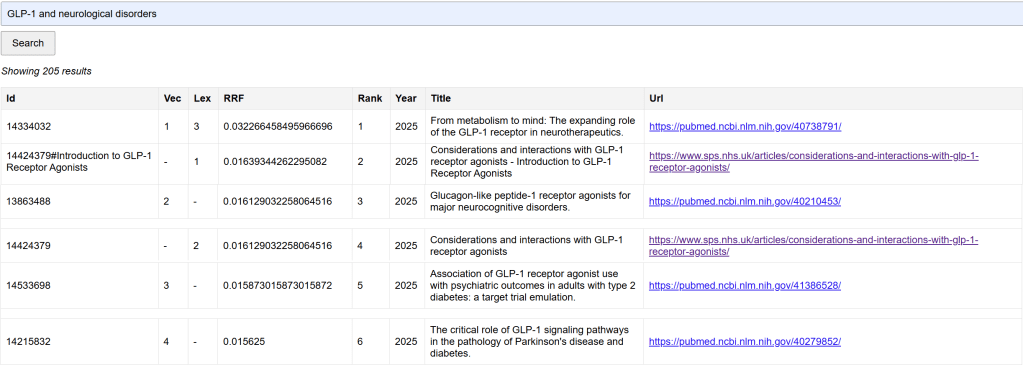
The top result appears in both the vector (Vec) and lexical (Lex) searches. Results #2 and #4 appear only in the lexical search, while #3, #5, and #6 appear only in the vector search.
The vector-only results do not contain the exact term “neurological disorders”. As a result, a traditional keyword-based search would have missed them unless extensive term expansion or synonymisation had been applied. This illustrates how vector search can surface conceptually related evidence that would otherwise be invisible to purely keyword-based approaches.
Another example comes from a search for “GLP-1 and anxiety”. The top results break down as follows:
Appeared in both vector (Vec) and lexical (Lex) searches
- Association of GLP-1 receptor agonist use with psychiatric outcomes in adults with type 2 diabetes: a target trial emulation
→ Top-ranked result in both searches
Vector (Vec) only — no explicit mention of anxiety
- GLP-1 medicines for weight loss and diabetes: what you need to know (section: GLP-1 medicines and mental health)
- GLP-1 agonists: depression, suicidal thoughts or behaviour? (GLP-1 agonists review)
Lexical (Lex) only
- GLP-1 receptor agonist use and risk of suicide death
- Anti-obesity medication guideline
The vector-only results are closely related to anxiety through overlapping concepts such as depression and suicidality, despite the term itself not appearing. This illustrates both the strength of semantic search and the potential for ambiguity in how relevance is interpreted.
Final thoughts
These examples highlight both the potential and the challenges of vector-based and hybrid search. The ability to surface conceptually related evidence that would be missed by traditional keyword search is powerful, while also raising important questions around relevance, explainability, and user trust – particularly in a clinical context.
We will continue to develop and refine this technology, with the intention of rolling it out across Trip and AskTrip in the near future. Our focus is on striking the right balance between precision and discovery, and ensuring that any changes meaningfully improve the search experience for clinicians and information specialists. This represents a significant evolution in how Trip works.
Crucially, this will remain a user choice. Users will be able to opt in to – or opt out of – vector-based and hybrid search, retaining full control over how their searches are performed.





Recent Comments