Years ago I did a lot of work on social network analysis, but I then moved away from the area. However, my interest got renewed when I read this article in PLOS ONE Clickstream Data Yields High-Resolution Maps of Science.
Clickstream data is the data a website records when a user comes to the site. In the case of Trip a user would visit the site, conduct a search and then click on a number of articles. Below is an example set of data:
0blzia55j3krmi55nuqc24nc 11/07/2013 Pregnancy UTI 5
0blzia55j3krmi55nuqc24nc 11/07/2013 Pregnancy UTI 6
0blzia55j3krmi55nuqc24nc 11/07/2013 Pregnancy UTI 7
0blzia55j3krmi55nuqc24nc 11/07/2013 Pregnancy UTI 8
The first column is the session id, second is the date, third is the search term used and the 4th is the unique document ID (this is typically a long number but I’ve transformed it for the sake of the analysis). So, in the above example, a user search for pregnancy UTI and clicked on documents 5, 6, 7 and 8.
Big deal you may say! Well, I think it is a big deal, I think it has the potentially to be really important. And here’s why. The user came to Trip with an intention and they have clicked on documents 5-8. They have told us that, for their search intention, those documents are linked. The ‘intention’ bit is vital as search is improved if we have more knowledge about the users intention. In isolation this might be meaningless, but over thousands of users you get lots of really useful data. Data that can be analysed. Below is an network map I produced (crudely as I’m not skilled in social network software packages). NOTE: for those eagle-eyed it’s not based on the same data as the example data given above.
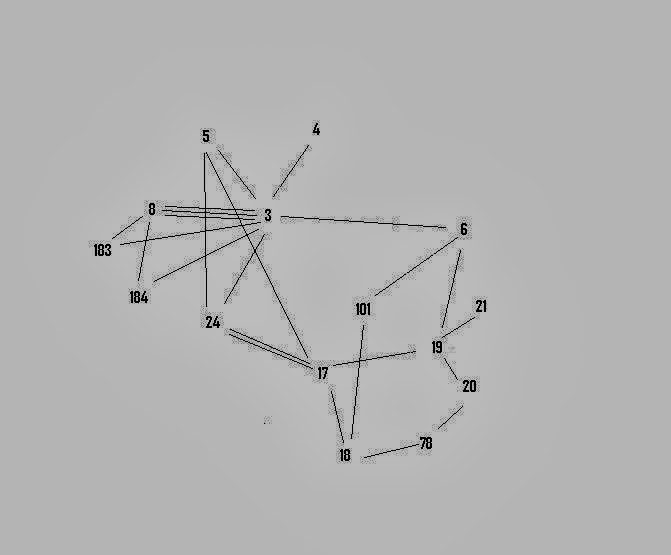
Each number represent a unique article and the lines represent a relationship between them (a relationship is formed when a user clicks on the two articles in the same session).As you’ll see there is a structure, and where there is structure there is value. I’m not talking financial value.
I was convinced that there would be a structure to the clickstream data, which is correct (as shown above) and I’m convinced that there is value in the structure. That’s the next step, to understand it. I’m got some help in analysing the key structural elements (of a sample of searches for UTI) and from there, who knows. I’ll report back ASAP.
In the interim, from the same website as above (Orgnet) I highlight two articles for interest:

October 15, 2013 at 1:22 pm
Clever and interesting.
LikeLike
October 15, 2013 at 8:07 pm
Really interesting. I wonder if could be useful to set up patterns when screening for systematic reviews. Can we create a network of included studies? Really suggesting ideas to follow!
LikeLike
October 25, 2013 at 2:14 pm
This might be very useful for anyone conducting either an integrative review or a systematic review, as a cumulative record of topic searches would indicate missing articles, along with articles to be considered for inclusion, that may not have been found by the original search strategies.
LikeLike