For 30 years, Trip Database has helped clinicians find the evidence they need. Search has always been at the heart of what we do and we’ve been quietly working on making it significantly better. Here’s what we’ve learned so far, and what we’re doing next.
The problem with traditional search
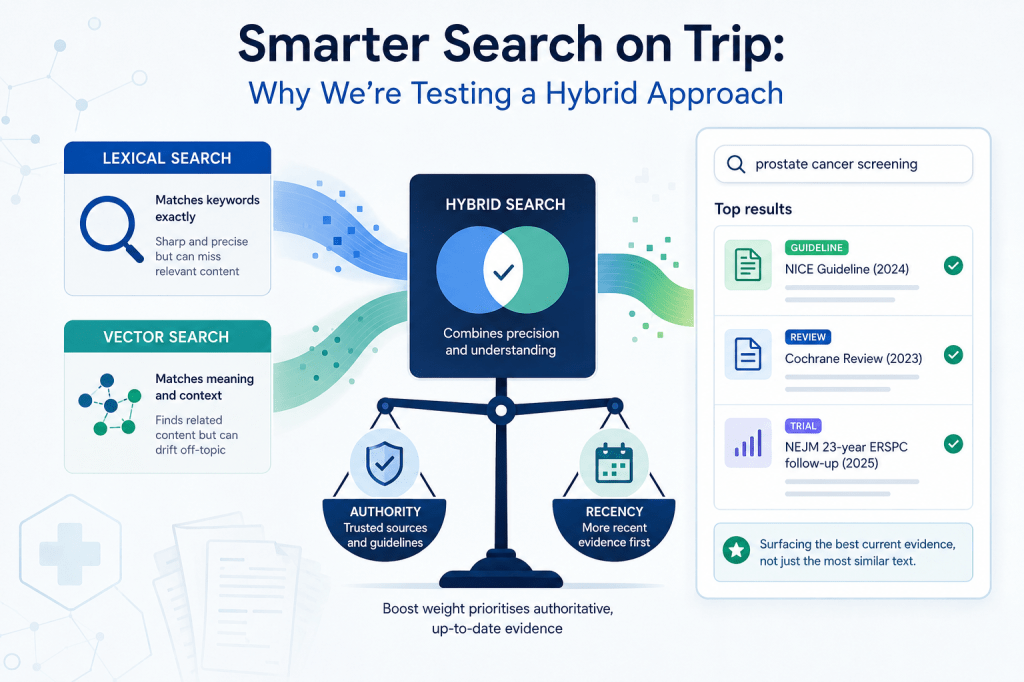
Until recently, search engines like Trip’s worked on a fairly simple principle: match the words in your query to the words in the documents. Type “heart attack,” and the system looks for documents containing “heart” and “attack.” This is called lexical search, and it’s been the backbone of search for decades.
It works well, until it doesn’t. Lexical search has a few well-known weaknesses:
- It doesn’t understand synonyms. Search for “heart attack” and you might miss documents that only use “myocardial infarction.”
- It doesn’t understand meaning. A search for “drugs to lower blood pressure” won’t necessarily find documents about “antihypertensive therapy,” even though they’re about the same thing.
- It can’t connect related concepts. Searching for “smoking cessation” might miss highly relevant documents on “tobacco dependence treatment.”
For clinicians searching evidence, where the same concept can be described in half a dozen ways across guidelines, trials, and reviews, these gaps matter.
Enter vector search
A newer approach, called vector search (or semantic search), tries to fix this. Instead of matching words, it tries to match meaning.
It works by converting every document – and every query – into a long list of numbers called a vector. Documents about similar topics end up with similar vectors, even if they use completely different words. So a search for “heart attack” can match documents about “myocardial infarction” because the system understands they mean the same thing.
This sounds like a clear upgrade. And in many cases, it is. But it has its own weaknesses.
But vector search isn’t perfect either
The catch is that vector search can be a bit too enthusiastic about finding related content. Search for “asthma” and a pure vector search might pull in documents on allergies, anaphylaxis, or even drug background pages – because they’re all in the same semantic neighbourhood. They’re related, but they’re not what the clinician asked for.
Lexical search, by contrast, is sharp and literal. If you search for “asthma,” it gives you documents about asthma. Sometimes that’s exactly what you want.
Our solution: a hybrid approach
So rather than choose one or the other, we’ve been testing hybrid search – combining lexical and vector search together, taking the best of both.
But “hybrid” isn’t a single thing. There are many ways to combine the two approaches, with different trade-offs. We tested five different configurations:
- Normal – pure lexical search (our current method, as a baseline)
- Hybrid – a balanced mix of lexical and vector
- Hybrid with higher semantic recall – a version that casts a wider semantic net
- Hybrid + boost weight – hybrid with extra weight given to authoritative sources and more recent evidence
- Hybrid with higher semantic recall + boost weight – the wider semantic net, also boosted
A quick note on what the boost actually does, because it matters. Our boost weighting rewards two things: authority (guidelines, Cochrane reviews, key primary research) and recency (a 2025 NEJM trial outranks a 2015 one; a current NICE guideline outranks an older synopsis on the same topic). For an evidence-based medicine tool, this combination is doing exactly what we want, surfacing the best current evidence, not just the most semantically similar text.
We tested each configuration on a range of clinical queries and assessed how well the top results matched what a clinician would actually want.
What we found
Three clear results emerged:
The boost matters – a lot. Adding extra weight to authoritative and recent sources made a big difference. Hybrid + boost weight was the strongest overall, winning on complex clinical queries like “anxiety AND psychological therapies” and “prostate cancer screening.” It consistently surfaced landmark studies like the 2025 NEJM 23-year ERSPC follow-up and the 2024 JAMA ProScreen trial that other methods missed or buried.
More semantic recall isn’t better. Casting a wider semantic net actively hurt performance. The extra results were mostly noise – documents that were semantically nearby but not what the clinician was looking for.
But here’s the twist: lexical search won on broad single-term queries. When we searched simply for “asthma,” the plain lexical method beat all the hybrid variants. Hybrid search drifted into related-but-not-quite-right territory (allergies, anaphylaxis, drug background pages), while lexical search sharply surfaced the canonical asthma guidelines.
This was the most interesting finding. It tells us there’s no single “best” search method, the right approach depends on the type of query.
What’s next: more internal testing before going live
Our results so far are encouraging but the evidence base is small – five methods across three queries. That’s enough to spot patterns, but not enough to commit to. Before we go anywhere near live testing with real users, we want to widen the evidence base internally.
We’re expanding the offline evaluation to a larger, deliberately mixed set of queries – probably 20–30 to start. Crucially, we’ll stratify these across the query types we’ve already identified:
- Simple single-term queries (asthma, diabetes, migraine) — where lexical search surprised us
- Topic + intervention (asthma inhaled corticosteroids)
- Topic + evidence or action (prostate cancer screening)
- Multi-concept Boolean queries (anxiety AND psychological therapies)
- Natural-language clinical questions (what’s the best treatment for…)
There are a few specific things we want to pin down:
- Does the asthma pattern generalise? Is lexical-led search genuinely better for broad single-term queries, or was asthma a lucky case where the corpus happens to have a perfectly-titled canonical guideline? Other single-term queries – Sjögren’s syndrome, functional neurological disorder – might behave differently.
- Where exactly is the crossover point? At what query length or complexity does hybrid + boost start to beat lexical? Where does a two-word query like “asthma management” fall?
- How robust is the boost? We know it helps, but the current weighting may not be optimal. There’s tuning to do on the relative weight of authority, recency, and semantic match.
- Where does each method fail? As important as knowing where things work is knowing where they break – queries where every method returns poor results probably need a different intervention entirely.
Then live testing
Once the larger offline evaluation gives us more confidence, or surprises us, we’ll move to live testing. We’ll start by running the new method silently alongside the current one, logging what would have happened without changing anything users see. Then we’ll move to a live test where a small percentage of traffic sees the new ranker, and we’ll measure not just clicks but real signs of usefulness, did the clinician open the full text, save the result, or did they immediately search again because the result wasn’t what they wanted?
The internal work now is what makes the live work meaningful. We want to go into the live test with clear hypotheses, not open-ended curiosity.
The likely end state isn’t “replace the old search with the new.” It’s smarter than that: use lexical-led search for simple broad queries, and hybrid + boost for richer clinical questions – letting the system pick the right tool for the job.
We’ll share what we find.

Leave a comment