It is hopefully self-explanatory…
NOTE: click to enlarge
It is hopefully self-explanatory…
NOTE: click to enlarge
Trip has been operating for over 15 years and I can easily say we have arrived at the most significant breakthrough yet. It is still in our ‘labs’ section and still has much work to do before being rolled out. But, the path is clear and, finance aside, there is no reason why we can’t produce a significant increase in search performance.
In search a really important concept is intention. So, when a user searches they may add 2-3 search terms but what are they thinking about when they use those terms? For instance, and this is a true story, I showed Trip to a Professor of Anaesthesiology and asked for his views on the site. He came back saying that he was unimpressed! The reason – his interest was in awareness (as in, when a person is under anaesthetic are they truly anaesthetised or may they be aware) and when you search Trip for awareness you get lots of results, mostly on things like the awareness of public health messages! Another example I use to illustrate the point is the search pain. We return the same results whether the person is an oncologist or a rheumatologist – which to me is ridiculous – as the intention is likely to be significantly different. But, to date, there has been no good solution.
The below image (click to enlarge) shows a breakthrough.

In the image above there are 4 sets of results for the same search antibiotics. This is a test system and not based on the real Trip results. However, on the left-hand side we have the normal/natural results for the search antibiotics in the test system. In the top right set of results the natural results have been reordered based on the clickstream activity of the users of Trip, those who have not logged in (85%). At the simplest level this promotes results that have been clicked on and relegates those that have not been clicked. It really is more complex than that – but I hope you get the point!
But the bottom right is where the magic it. Even though it only accounts for 0.2% of the activity, we have reordered the results based on the clickthrough activity of dentists. There are a few erroneous results, but I’d like to think you can see the effect – dental articles are promoted.
So, the effect of this is that – when we eventually roll out the system – and we know the user is a dentist we improve their results based on the previous activity of other dentists. The reality is that this technique will work with any speciality and profession.
There are a few issues, the paucity of data is the biggest and we have two significant ways of tackling this:
Oh yes, we’ve even figured out a way to mitigate the effects of filter bubbles.
This really has been a good few weeks.
…is, I hope, not the light of an oncoming train. I’ve nabbed that line from my favourite band – Half Man Half Biscuit (HMHB) who wrote The Light At The End Of The Tunnel (Is The Light Of An Oncoming Train) a good few years ago! My love for HMHB aside, I keep reflecting on how things seem to be going really well for Trip and I’m desperately hoping we’ve turned a corner. So, why the optimism:
Long may this continue!
In the previous post (Clickstream data and results reordering) I highlighted how the clickstream data could be used to easily surface articles that are not picked up by usual keyword searches. That post highlighted how it could be used to improve search results. In my mind I was thinking this could help surface documents to improve a clinician trying to answer their clinical questions.
But what about in systematic reviews (or similar comprehensive searches)? A couple of scenarios spring to mind:
If there are any systematic reviewers/searchers I’d love to hear what you think!
Recently I’ve been discussing the potential for using our clickstream data (our earliest post on the subject being from October 2013). After a post earlier this year Ok, I admit it, I’m stuck I have been contacted by two separate people who have both been very generous with their time and on Friday I met with one of them who talked me what they had found.
Before I share the results there are a few points to consider:
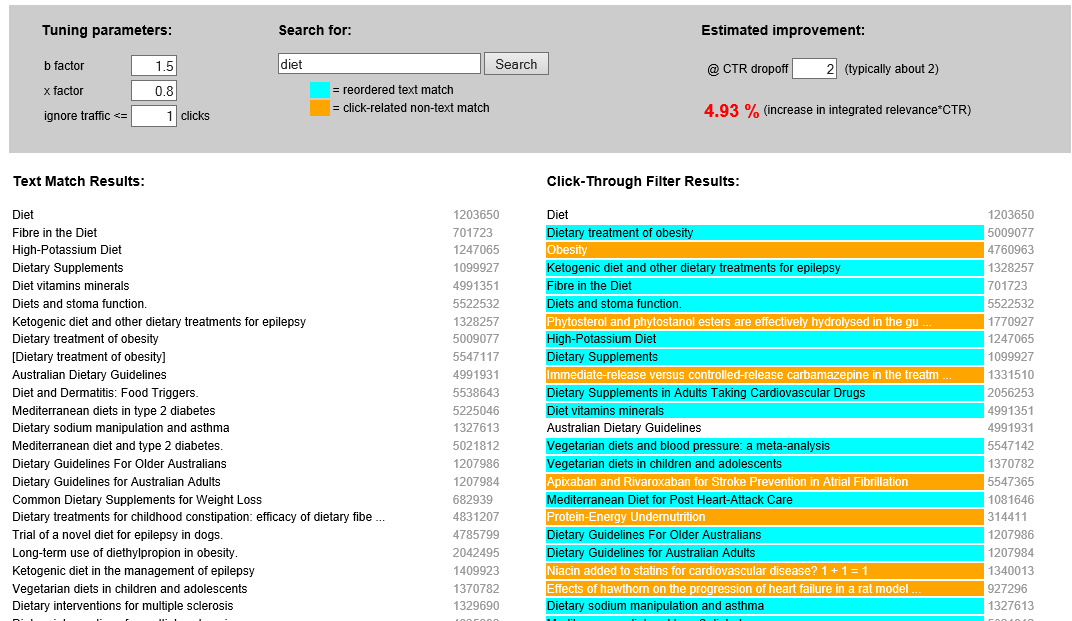
So, what’s going on?
The left hand side are the results in this mock-up search. However, those on the right-hand side have been reordered using simple clickstream data. Those articles that are surrounded by the light blue colour have been boosted (so appear higher) due to lots of people clicking on them. Those results surrounded by orange are arguably more interesting – as they don’t include the search term in the title!
What this signifies is that users of Trip, while searching the actual Trip, have clicked on the orange articles in the same search session as one of the articles on the left-hand side. So, it’s telling us that the orange articles are related to the normal results – and being inserted into the results – even though they were not matched in our search test by having the word diet in the title.
Trying to describe this in the blog is slightly difficult as I’m not sure if I’ve explained it particularly well. I suppose there are two take homes:
In my previous post Ok, I admit it, I’m stuck (a title people seem to really like) I highlighted the difficulty in finding meaning in our clickstream data (the data generated by users interacting with the site). One thing that I had thought about and a couple of people have subsequently raised is an Amazon style ‘People who looked at this article, also looked at this one..’, a feature I find really interesting and frequently useful.
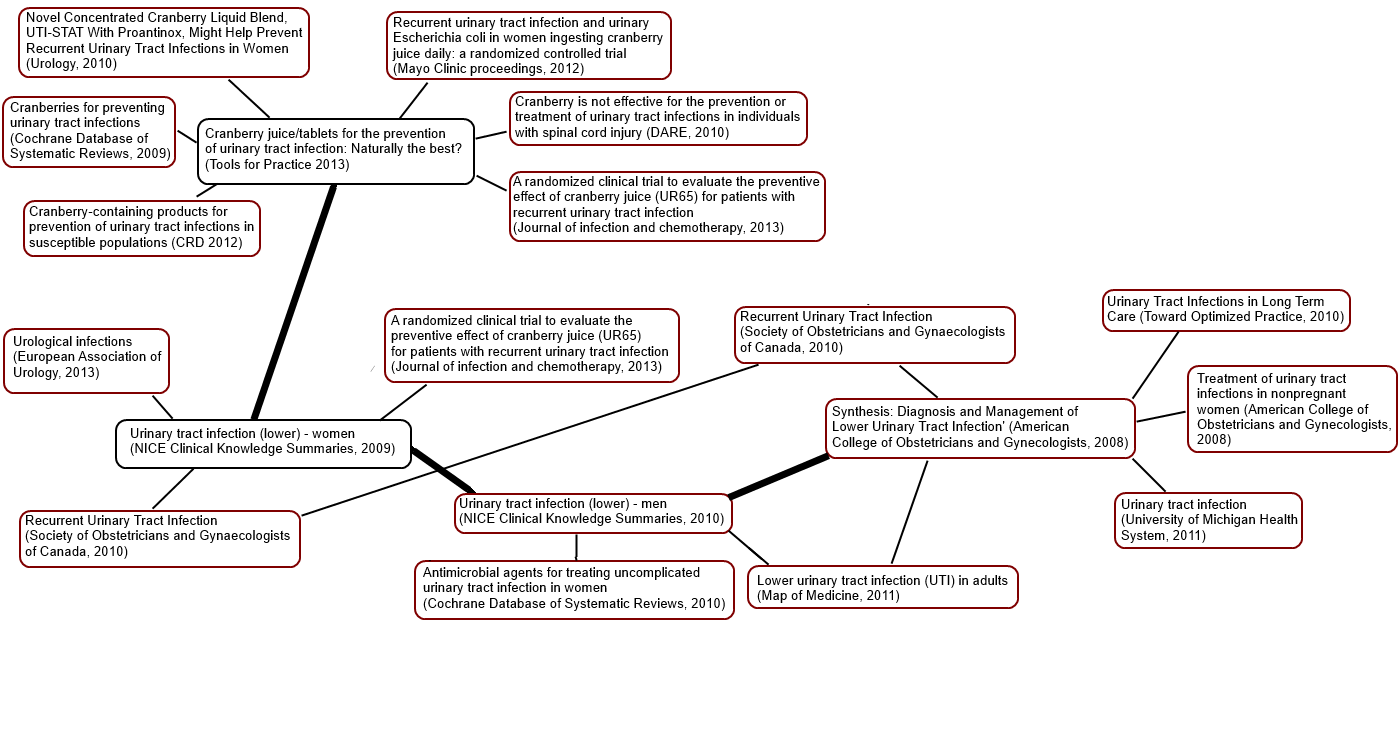
So, taking some earlier work on mapping UTI data I started doing further analysis but it was based on this graph.
I started with an article that looked in an interesting place and picked document 2056462 (Cranberry juice/tablets for the prevention of urinary tract infection: Naturally the best? from the publication Tools for Practice 2013) and then followed the links from there. Some have since been removed or updated. But, we can say that ‘People who looked at Cranberry juice/tablets for the prevention of urinary tract infection: Naturally the best? also looked at…
I then, as a way of snowballing, took the last article in the list and did a similar thing, which results in ‘People that looked at Urinary tract infection (lower) – women also looked at…
Anyway, I hope it’s clear what’s going on! On one level it all seems good and interesting in that all the articles seem relevant. But does it add anything that the initial search wouldn’t have found? To help I’ve gone through the top list and shown where each of the results appears in the search results (coincidentally the Tools for Practice article came 5th in the results list for a search of urinary tract infection and cranberry):
To me these results are interesting! The clear ‘outliers’ are the top and bottom results which appeared in result number 38 and 54 respectively. This is important as it means that they are much less likely to be seen – especially the latter one which would be on the third page of results.
Is this useful?
It will highlight different articles than found from browsing the search results, but is there a cost? Will users look less at our algorithmic results (the normal results) and rely on these ‘human’ results? If so, is that good or bad? I actually think it’ll encourage people to explore more and spend longer on the site – so I don’t think it’ll have a negative consequence.
This is really interesting!
I’m really tempted to open a can of worms by asking if there is any coherence/rationality as to how the linked articles list is generated. However, as the above list is based on only a sample of data it’d be wrong to place too much weight on things. Also, even if it is random, so what!?
Finally, I’ve even graphed this out (in not too an appealing way):
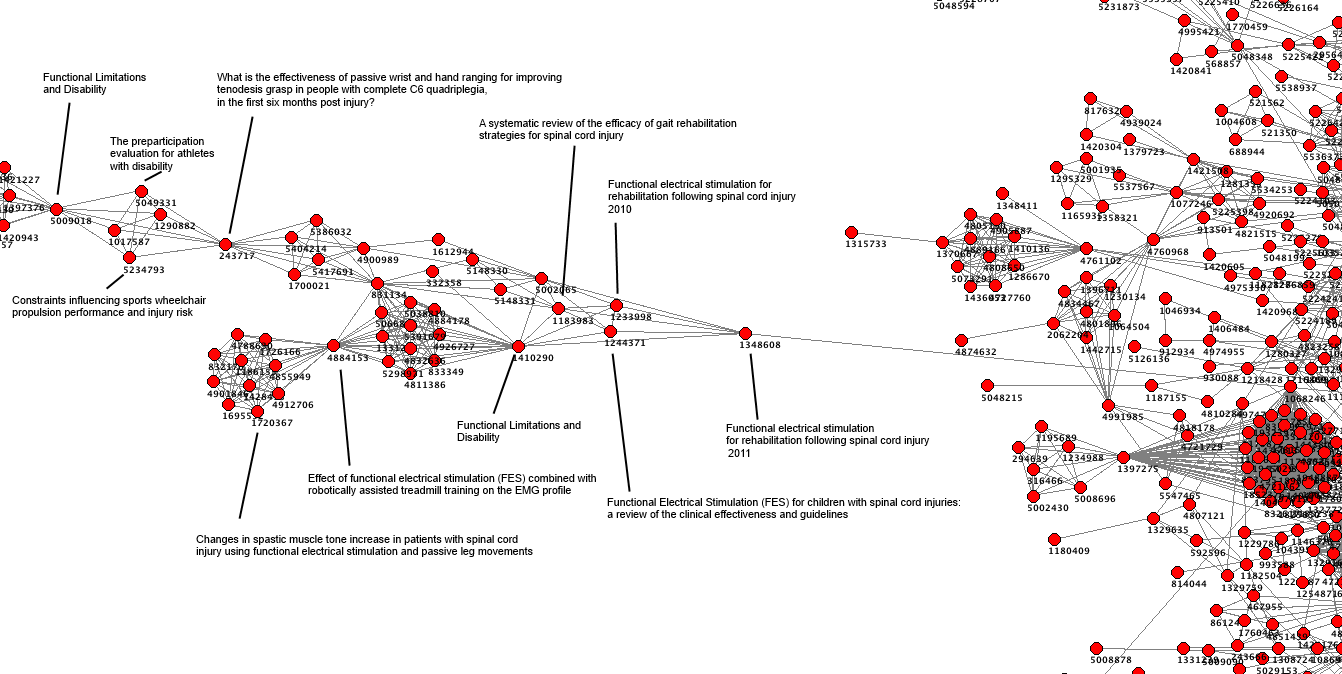
I’ve been talking about article social networks for a while, and last August I wrote ‘Beauty is in the eye of the beholder‘ which contained the image below.
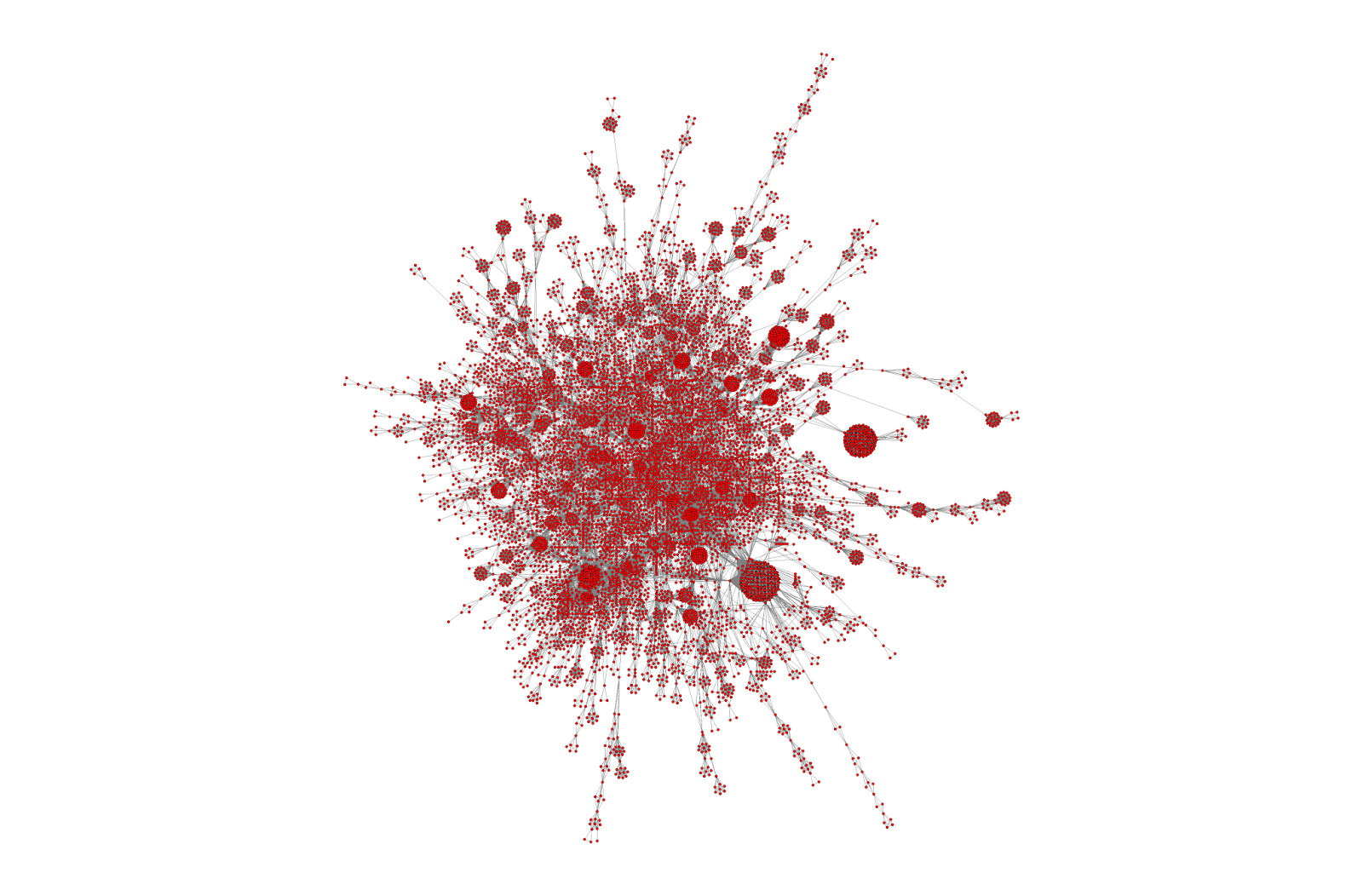
I’ve continued to be fascinated by them and below are two more images – focused on defined areas of the above graph
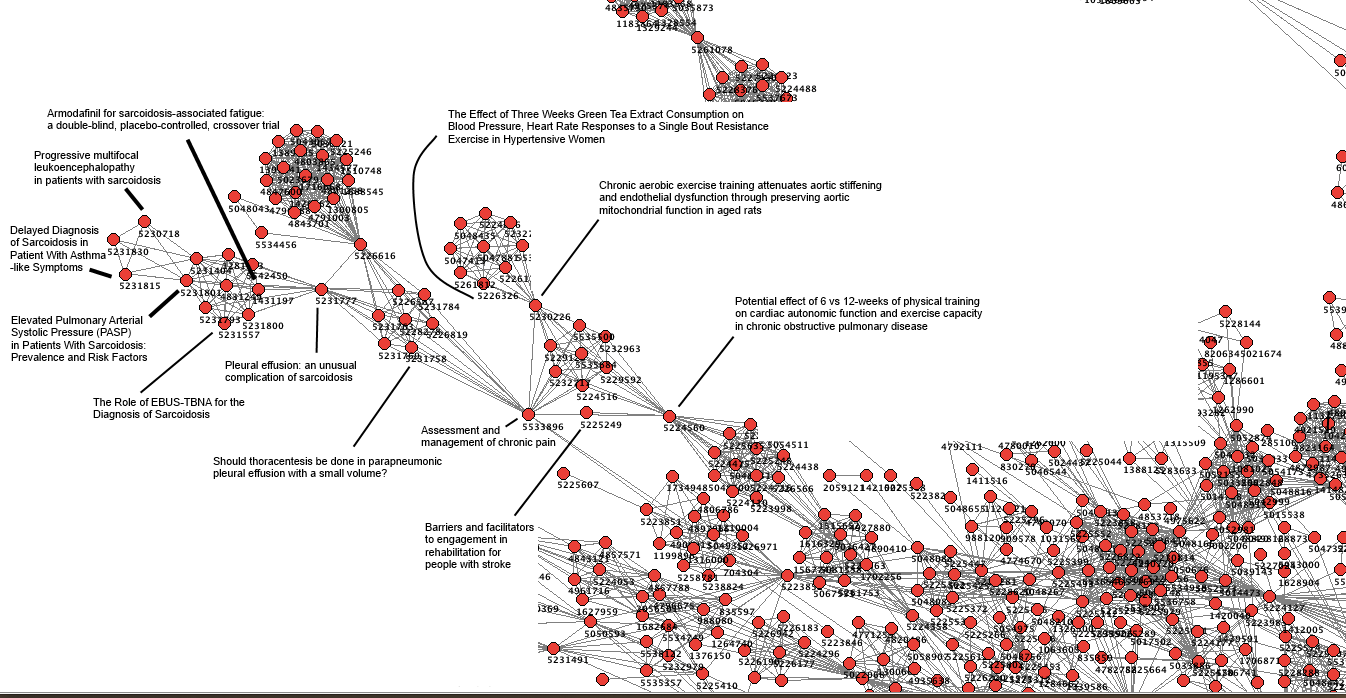
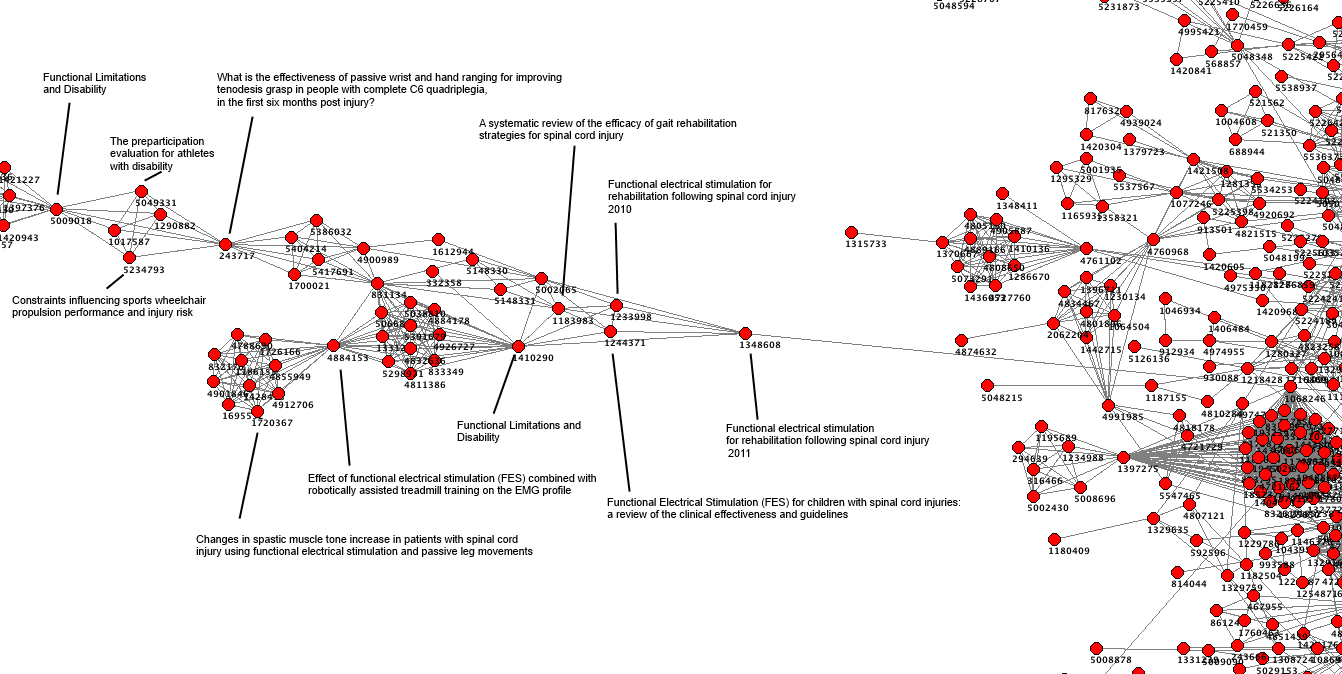
These are beautiful – but is there more to it?
Both images show definite structure. So, our users, simply by using the site are adding structure and energy. I keep getting drawn to the principle of entropy. I’m absolutely sure that our users are ordering the articles in Trip but does that have any value?
I admit to being relatively clueless – part of the purpose of the post is to see if the wisdom of the Trip users can be brought to bear to try and help me figure out what the above might mean and what might the next steps be!
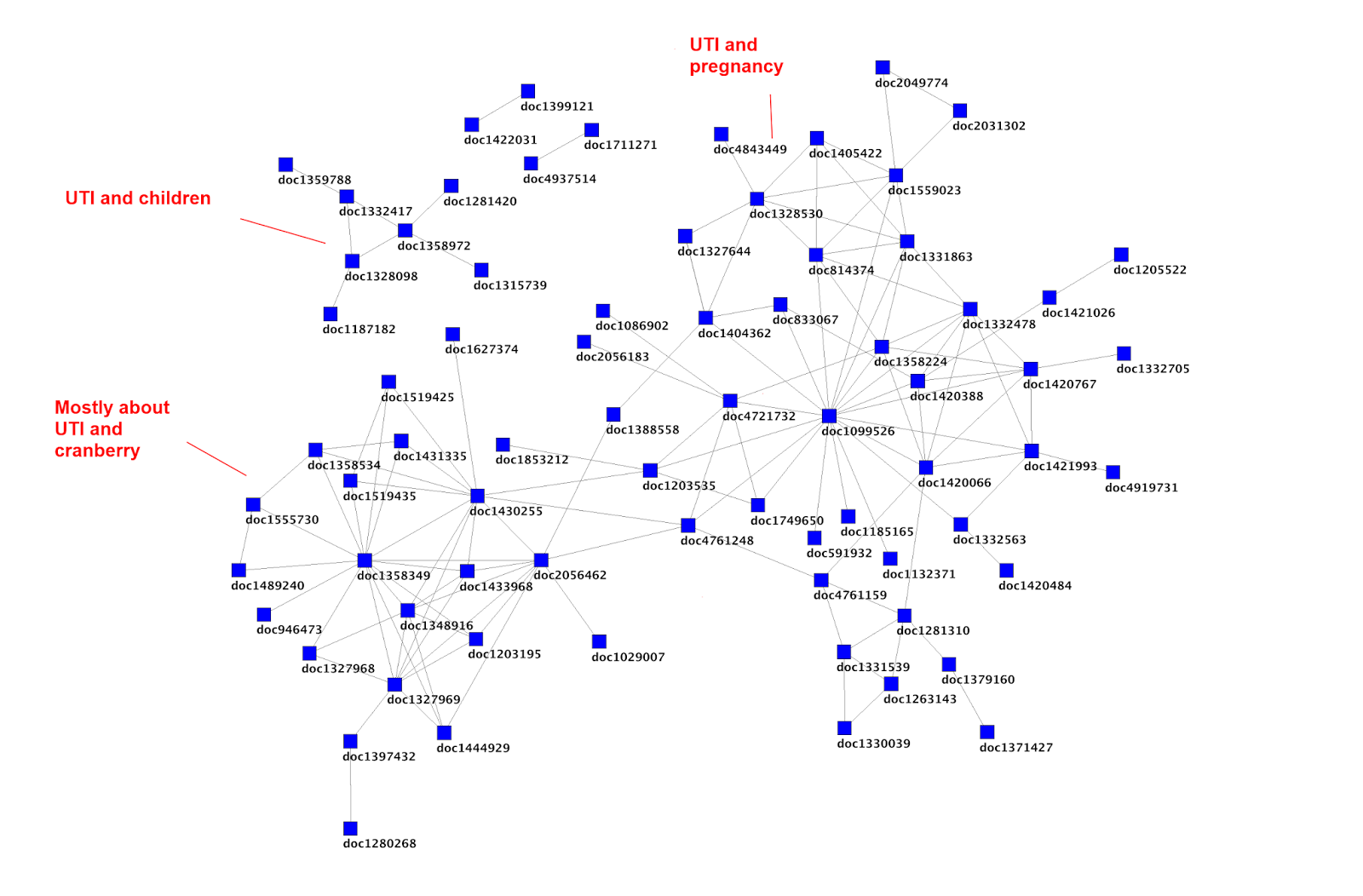
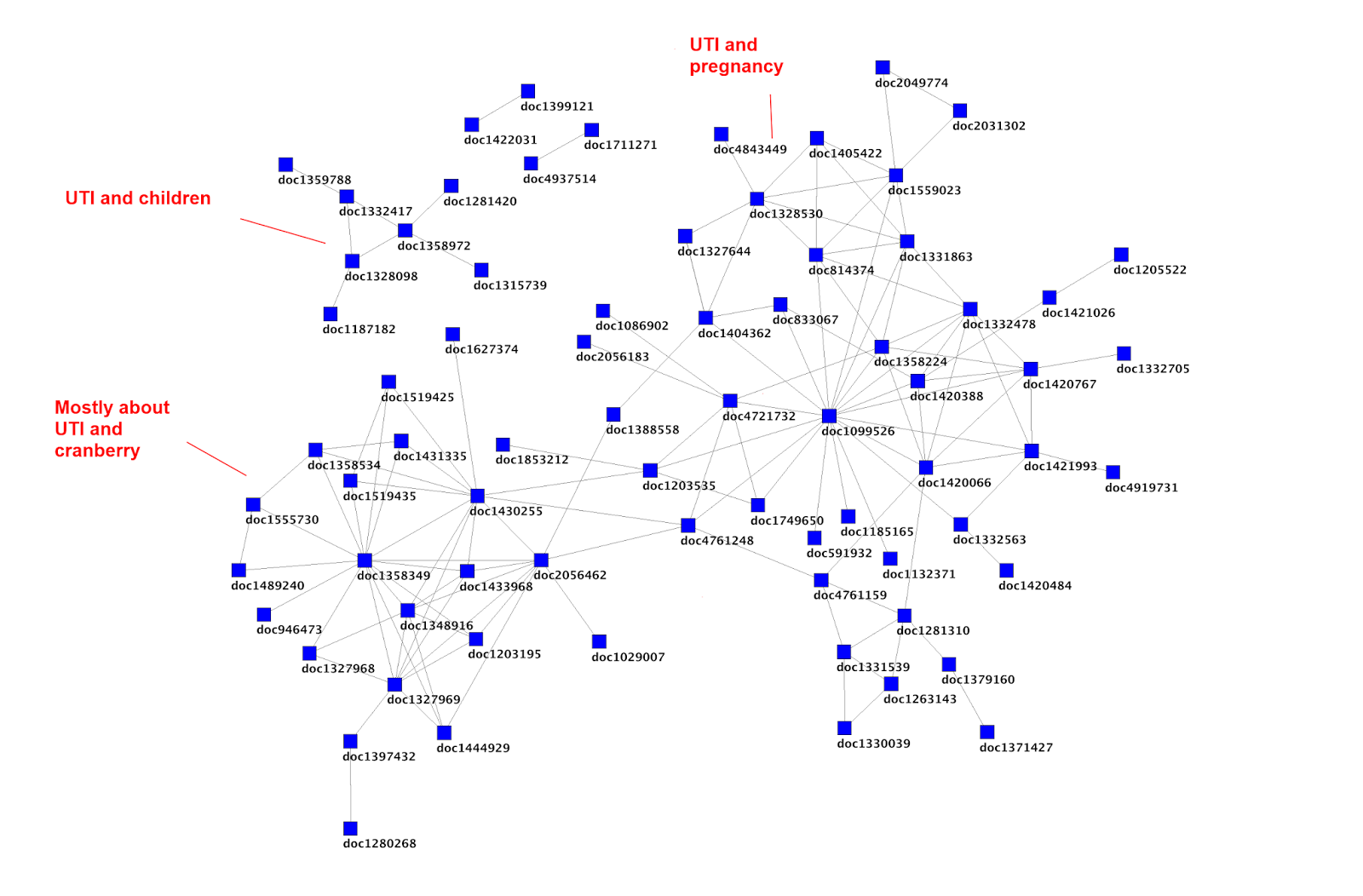
The above image (taken from Article social networks, meaning and redundancy) shows distinct clusters as well. In the bottom left is a cluster of articles on UTI and cranberry and it consists of 19 articles. If you do a search of Trip you find many more than this. So, our users are not clicking on many articles – so as well as adding structure are they giving us clues as to articles that aren’t worthwhile (based on their collective judgements)?
If you click on one article in that cluster, is it likely that the others will be worthwhile? What about if a new article is published and joins the cluster based on another person searching and effectively adding the article to the cluster – is that useful? I’m sure there are no absolutes, but these appear to be hints – surely?
A final thought – the graphs are based on all users. I imagine the above graph would look different if the user had been a general/family practitioner compared with, say, a urologist. Stronger clues?
I would be absolutely delighted if anyone can help me figure out the value/meaning of the data. And, if you can think of ways of working together I’d be delighted to see how we can share the data!
At the end of 2013 I did a review of the year and now, in early 2015, I thought I’d repeat the exercise for 2014!
First, the stats:
The above represents an ongoing trend which is seeing less unique users but the ‘quality’ is higher in that the users are more engaged and making better use of the site. It is this engagement that is so satisfying, much more important than some – ego boosting – headline of number of unique visitors (although 3.6 million page views is quite impressive)!
Financial insecurity has been a recurring theme for Trip and I’m really pleased as I think we’re fine for now and this is based on two facts:
At the end of 2013 I reported on the disappointment of missing out on an honorary professorship but I was very pleased to be given an honorary fellowship at the Centre for Evidence-Based Medicine (CEBM) at Oxford University. The CEBM runs the wonderful Evidence Live series of conferences and I’ll be involved again in the session ‘EBM into Practice: Future of evidence synthesis: a new paradigm’ which will be alongside Carl Heneghan, Martin Burton and Tom Jefferson.
Other bits and bobs from the year:
Other than the above there have been so many other things but many are important to me but probably less so to others.
There is also another, really major, project I’m starting to explore but for various reasons I can’t share now. But it builds on the answer engine concept but there is the potential for Trip to work with a huge commercial partner.
Finally, a very large thank you to:
2014 has been great and I hope – given the reduced financial stress – 2015 will be even better.
For those of you who’ve followed this blog for a while will see that I’m always revisiting the answer engine concept, most recently two months ago. A month before that I mentioned it in the context of a a Journal of Clinical Q&A.
This all stems from my belief that Trip is a wonderful tool to answer clinical questions but a also belief that it could be even better! After all, it was the reason I started it in the first place – to help me answer clinical questions via the ATTRACT Q&A service. Surveys have shown that many clinicians agree, with over 70% of questions, supporting clinical care, are helped by using Trip.
Recapping briefly on the answer engine and the Journal of Clinical Q&A:
So far, fairly radical and fairly good.
Now, another variable to consider – the PICO search system. In the forthcoming upgrade we’ll be enhancing this feature in the premium version. It will be more guided than the existing version and it could work like this:
Another powerful component for a Q&A environment, what could go wrong (I ask tentatively!)?
 I
I 
Recent Comments