Trip introduced the freemium business model around ten years ago. It was our approach to remaining both viable and independent. The fact that we’re still here (and doing well) is some validation of our approach.
Subscriptions are available for individuals at $55 per year while institutions can subscribe, with costs dependent on both their size and organisational ‘type’ (click here for current prices).
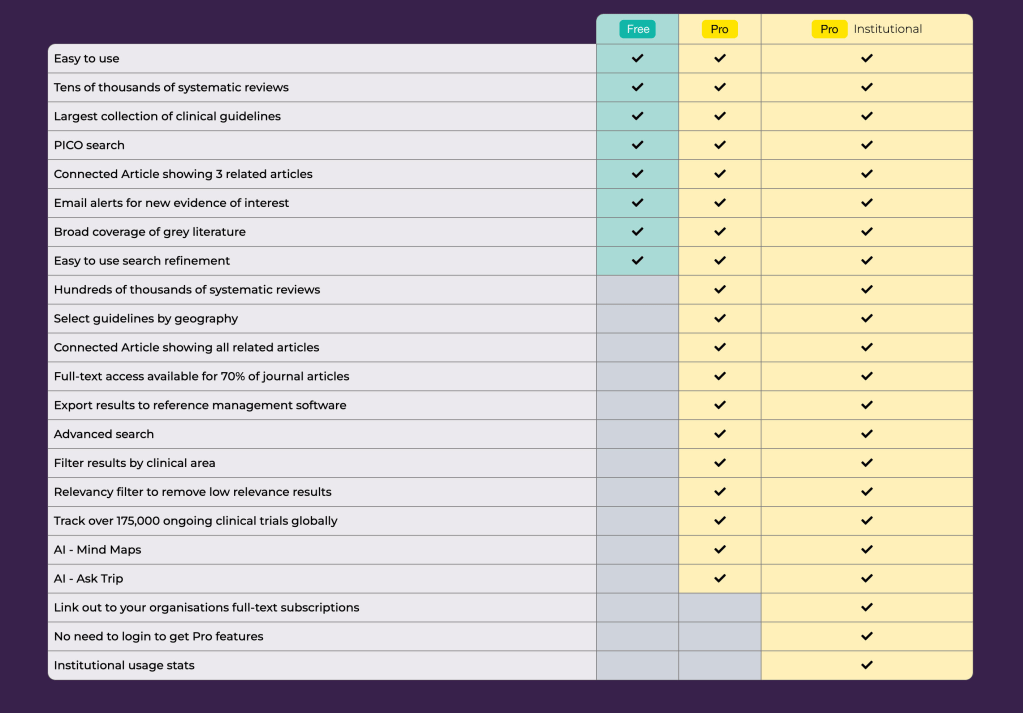
But what do you get for the subscription? Below is an overview of the differences and as we develop new features these will mostly favour Pro subscribers:
We are absolutely delighted to announce the release of our automated clinical Q&A system – AskTrip. If you follow the blog you’ll appreciate the effort we’ve put in to create the system and we’re delighted to finally make it available to you.
What is AskTrip? AskTrip is an AI-powered clinical question-answering system built on the trusted foundation of the Trip Database. It delivers evidence-based answers to clinical questions in 30 seconds, drawing from Trip’s extensive search index to ensure the most current and relevant information.
AskTrip isn’t just smart; it’s transparent. Each answer includes links to the underlying evidence, so users can explore the sources themselves and assess their quality. Behind the system lies over 25 years of experience answering clinical questions manually – more than 10,000 Q&As – which has shaped both the structure of the answers and the types of queries the system handles best.
In short, AskTrip combines the speed and scale of AI with Trip’s proven expertise in evidence-based medicine, helping clinicians get trusted answers in seconds.
Access is via links at the top of the main Trip site and from the search results page:
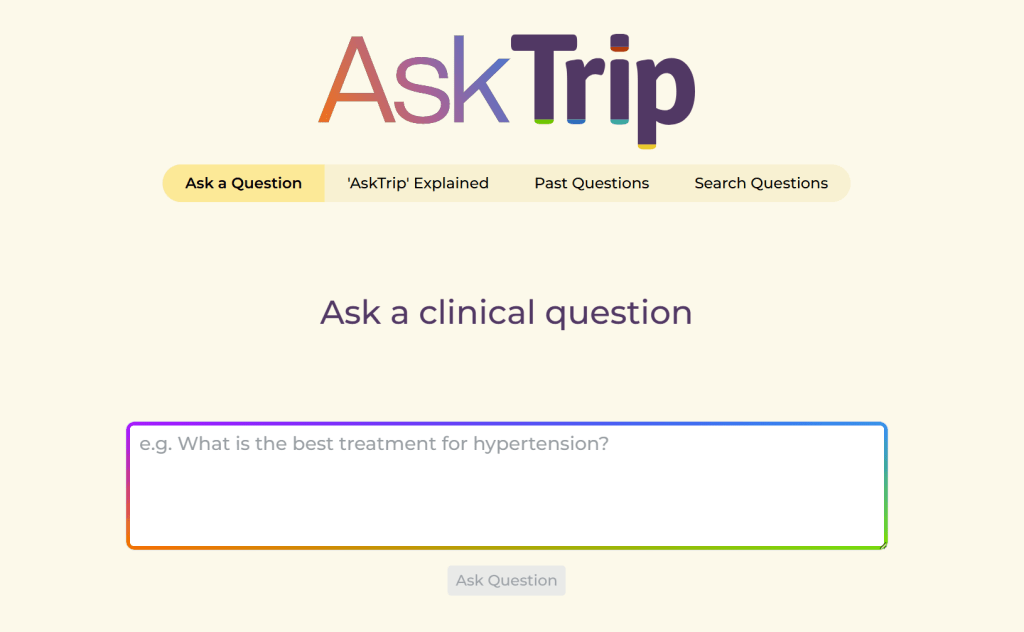
Landing page
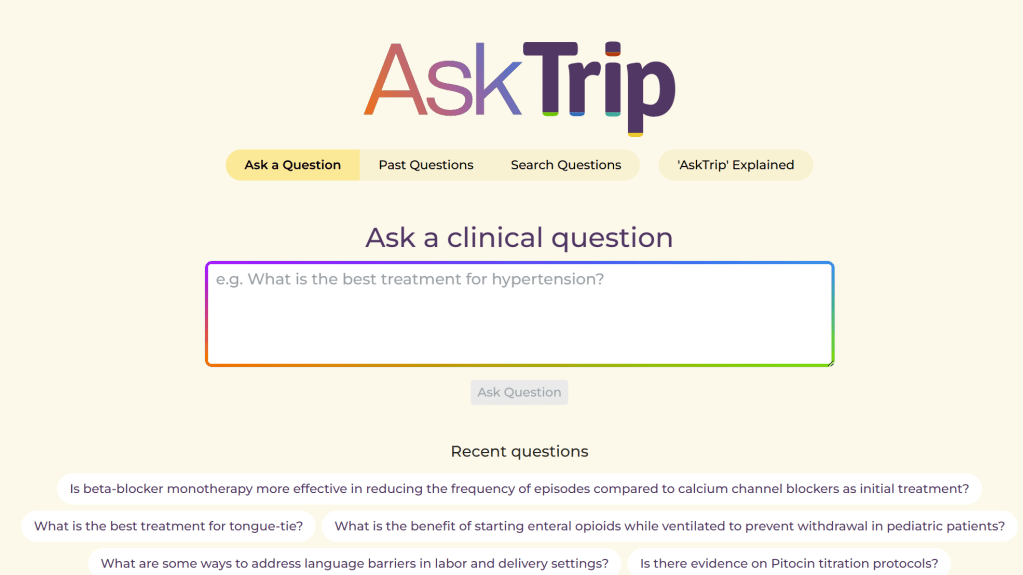
The landing page for AskTrip looks like this:
At the bottom you’ll see the most recent questions and above Ask a clinical question you’ll see four options:
Ask a question
Past questions
Search questions
‘AskTrip’ explained
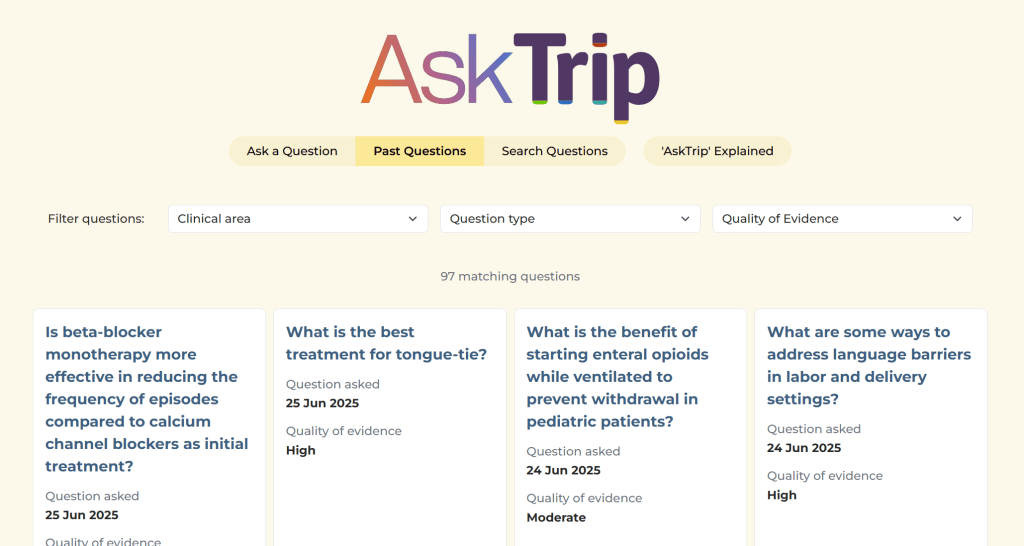
Past questions
This allows you to browse questions and you can filter these by clinical area (e.g. cardiology, oncology), question type (e.g. diagnosis, management) and quality of evidence (moderate to high).
In our past Q&A systems (such as ATTRACT) users said they enjoyed looking at questions other health professionals had asked, and that was for two main reasons:
They felt good if they knew the answer.
They didn’t know what they didn’t know.
We can’t help feeling that this curiosity will still be there and that browsing questions will be a great feature of the site.
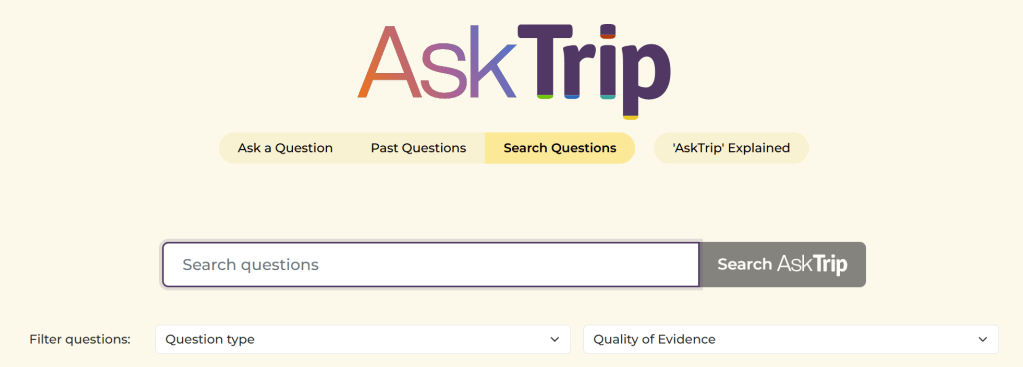
Search questions
Enter your search terms and there are options to filter the results by question type and quality of evidence.
‘AskTrip’ Explained
This is a bit of background about the site and also a high-level explanation of how the system works.
Show original question – in the beta we noted that people would ask poorly formed questions, so our system tidies them up. Clicking on the link allows you to see the original question
The foot of the answer looks like this:
References
Report an issue – given the nature of the site it’s important to allow users to report a question they believe is sub-optimal.
Handy extras worth knowing
Free vs. Pro access – Free users of Trip will have three free questions per month while Pro users will have unrestricted access.
Road-map & feedback – We have ambitious development plans (e.g. multilingual, specific Q&A monthly emails, question trajectories) but if you’d like to see extra features then please let us know via suggestions@tripdatabase.com
Mobile optimisation – the site is optimised for mobile devices so – using your phone or tablet’s web browser – navigate to AskTrip!
Adding AskTrip to your website – We’re already in discussions with third-party organisations about embedding AskTrip directly into their websites and intranets. These tailored versions match the host’s look and feel, and can feature local clinical guidance, policy content, or risk advice – integrated alongside trusted, evidence-based answers. It’s your voice, delivered at the point of care.
In conclusion
We built AskTrip to put high-quality evidence in your hands within seconds. Whether you’re a long-time Trip user or completely new, we’d love you to take AskTrip for a spin, push its limits, and tell us where it shines – or where it can do better (use feedback@tripdatabase.com). Your real-world questions are what will make the system smarter over time. Give it a try today and let us know what you think—together we can turn good evidence into great care, faster than ever.
Finally….
There are a number of people that deserve thanks in getting this over the line:
Beta testers – A small group of users asked over 500 clinical questions during the beta phase. Their persistence and repeated use gave us confidence that AskTrip was solving a real problem. Their thoughtful feedback played a major role in shaping and improving the system. We’re hugely grateful.
Abrar – one of our developers, while not involved in the main AskTrip work was instrumental it getting it live.
AD – our designer, he designed and developed the ‘front end’ of the site – he’s done a fabulous job.
Phil – Phil has been part of Trip for over 20 years as our lead developer. While Abrar now handles most of the day-to-day development, Phil continues to play a vital role in shaping Trip’s direction. For AskTrip, he took on the vast bulk of the coding – and it’s fair to say this feels like his finest contribution yet. The quality, care, and scale of his work have been immense. Like a fine wine, he just keeps getting better. I couldn’t be more grateful.
When answering clinical questions, it’s not enough to simply provide an answer – it’s essential to communicate how strong the supporting evidence is. Because our Q&A system is automated, we’ve developed a pragmatic yet transparent way of scoring the strength of evidence behind each answer.
How We Classify Evidence At the core of our approach is how we classify the references used to generate an answer. For simplicity, we’ve grouped the sources into four categories:
Essential – The highest quality sources, such as NICE, AHRQ, guidelines; especially when they are up to date.
Desirable – Other high-quality secondary evidence (e.g. systematic reviews) and key primary research studies.
Other – The rest of the content in Trip e.g. peer-reviewed journal articles, eTextbooks.
AI – Content that is generated primarily through the large language model (LLM), used when evidence is sparse or missing.
The Scoring System Each answer is scored based on the proportion of higher-quality evidence (Essential and Desirable) it includes:
High – 75% or more of the references are Essential or Desirable
Good – 55–74% are Essential or Desirable
Moderate – Below 55% Essential/Desirable
Limited – 50% or more of the answer is generated by the AI (i.e. minimal reference support)
A Nuanced Interpretation This system produces some interesting situations. For example, an answer may score High if it’s based entirely on high-quality sources – even if those sources all agree that the evidence is limited or conflicting. In other words, a High score reflects the confidence in the evidence base used to construct the answer, not necessarily that the answer is definitive or conclusive.
We believe this approach strikes a useful balance between automation and transparency. It allows users to quickly gauge how much trust they can place in the evidence behind each answer, while also recognising the complexity and occasional uncertainty inherent in clinical decision-making.
98% of the core Q&A work is complete and now we’re mainly testing and correcting minor issuess…
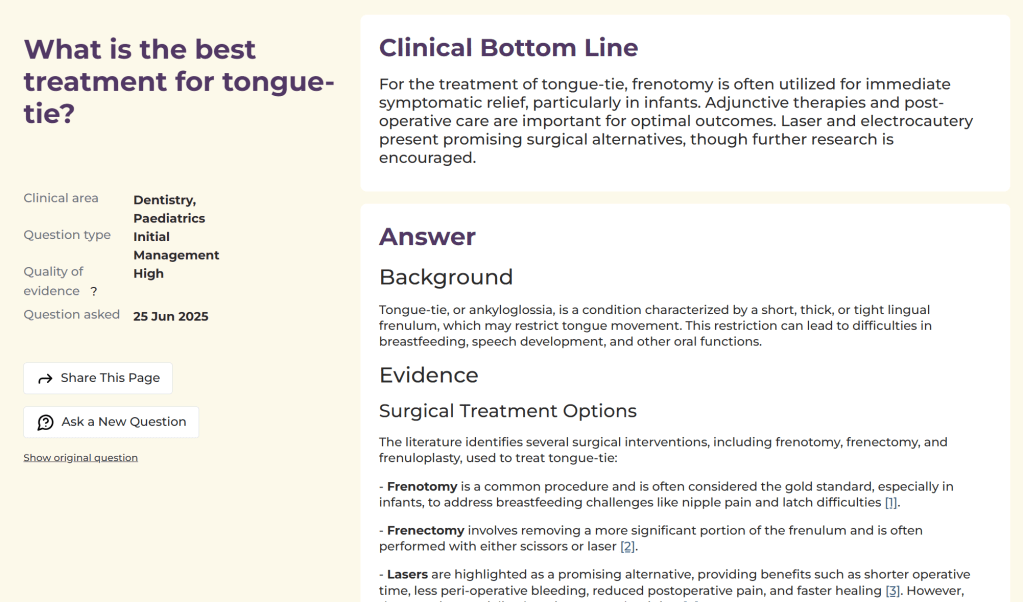
The main AskTrip page will look like this:
While an answer page looks like this:
Lots to see here:
References are now looking lovely – in the beta this was the biggest bugbear of testers!
Clinical areas – to help users browse Q&As of interest
Clinical type – it should actually be ‘Question type’, these include causes, treatment, complication etc, a way of classifying Q&As to help browsing but also act as a timeline of a condition – one for a future project
Quality of evidence – how strong was the evidence in answering the question. Useful for users but also one for a future project
Show original question – we noticed, from the beta, that users didn’t always form perfect questions e.g. no initial capital letter, no question mark, odd spacing. Our system corrects that – for display – but the original question is available to be seen
Related questions – not the best examples, due to the lack of Q&As in this version of the site and ignore the numbers after each title, that’s for our testing. But this is showing users questions that are closely related to this particular question
Report an issue – if a particular answer concerns someone, they can easily report it to us to be checked by our medical team
Since the beta we’ve added a whole bunch of new features, many behind the scenes, so we’re delighted that the answers still come back in less than 30 seconds.
Release date – definitely by the end of the month, maybe as early as the end of next week!
The testing of the automated Q&A system is ongoing and yesterday I thought we’d hit a major problem – a poor answer!
A quick historical detour: around 15–20 years ago, while running the NLH Q&A Service for the NHS in England, the wonderful Muir Gray (who funded the service) was keen to identify frequently asked questions. One that consistently came up was: “What is the optimal frequency of vitamin B12 injections in pernicious anaemia?”
Fast forward to today. I tested that same question on our current Q&A system – and the results were underwhelming. Thankfully, thanks to Rocio, we had a full testing trace, letting me follow every step in the process. This led me to the NICE guideline Vitamin B12 deficiency in over 16s: diagnosis and management, which states: “In this guideline, we do not use the term ‘pernicious anaemia’ to describe autoimmune gastritis.”
Curious, I emailed Chris (our medical director) to ask whether “pernicious anaemia” is now considered outdated. His reply? “Pernicious anaemia is old hat – only old fogies like us still use that term!”
So, back to the Q&A system, I did two things:
Re-asked the question using autoimmune gastritis instead of pernicious anaemia = great answer..
Updated our synonym mappings to treat both terms as equivalent in search.
What started as a concern about system performance turned into a valuable reminder of how medical language evolves – and that I’m getting old 🙂
As part of the Q&A system we are minded that including patient identifiable information (PII) is a big no-no! So, as part of the initial question processing we have a ‘guardrail’ system to handle this eventuality!
Test Q (completely made up) : My patient (Mrs Jane Smith DOB 17/12/1856) has persistent vulvovaginal candidiasis not improving with prolonged fluconazole treatment. What investigations should I undertake and can you suggest some treatments?
Our system reported:
The question as written is problematic due to a violation of criterion (2): it includes patient identifiable information.
Issue (2): Inclusion of Patient Identifiable Information Name: “Mrs Jane Smith”
Date of Birth: “DOB 17/12/1856”
These are direct identifiers and must not be included in a clinical query, even in professional contexts where confidentiality is expected.
Corrected Version (with Identifiable Information Removed): Q: A postmenopausal woman has persistent vulvovaginal candidiasis that has not improved with prolonged fluconazole treatment. What investigations should I undertake and can you suggest alternative treatments?
The question processing stage is really interesting. As well as guardrail (stripping out PII, profanities etc) it’s correcting spelling, grammar, formatting. It’s assigning question type and clinical area(s). There’s a lot of activity before the search has even started.
We’re getting close…. The system was great before and it’s getting much much better!
We last tinkered with the journals list in 2022, so a refresh was long overdue.
At the moment Trip takes content from PubMed in three main ways:
A filter to ID all the RCTs in PubMed, whatever the source.
A filter to ID all the systematic reviews in PubMed, whatever the source.
All the articles from a core set of journals.
Core journals
When we first added journals to Trip around 1998–99, we started with 25 titles. This number grew to 100, then 450, and as of today, we include just over 600 journals. With the upcoming launch of our clinical Q&A system, we felt it was a good time to review our journal coverage with the aim of expanding it further.
We took a multi-step approach:
The Q&A system uses a categorisation framework based on 38 clinical areas. We used these categories to identify relevant journals in each category.
We excluded journals that do not support clinical practice—such as those focused on laboratory-based research.
We removed journals already included in Trip.
From the remaining titles, we selected those with the strongest impact factors for inclusion.
Additionally, since impact factors can undervalue newer journals, we manually identified promising new titles likely to be influential – such as NEJM AI – and added them as well.
The outcome of our review: we identified 281 new journals, which we’ll be adding over the next few days. This will bring our total to just under 900 journals. That feels about right—representing roughly 20% of all actively indexed journals in PubMed.
While we may continue to add the occasional journal in the future, it’s unlikely we’ll see an expansion of this scale again. There’s always a balance to strike between broad coverage and introducing noise – and we believe we’ve judged it well.
Rocio has been a wonderful supporter of Trip for years, and when she offered to test our Q&A system, she brought her usual diligence to the task. After trying it out, she emailed to ask why a key paper – a recent systematic review from a Lancet journal – wasn’t included in the answer. That simple question kicked off a deep dive, a lot of analysis, and a lot of work… and ultimately led to the realisation that we’ve now built a much better product.
At first, we thought it was a synonyms issue. The question used the term ablation, but the paper only mentioned ablative in the abstract. Simple enough – we added a synonym pair. But the issue persisted. So… what was going on? Honestly, we had no idea.
What it did make us realise, though, was that we’d made a whole bunch of assumptions – about the process, the steps, and what was actually happening under the hood. So, the big question: how do we fix that?
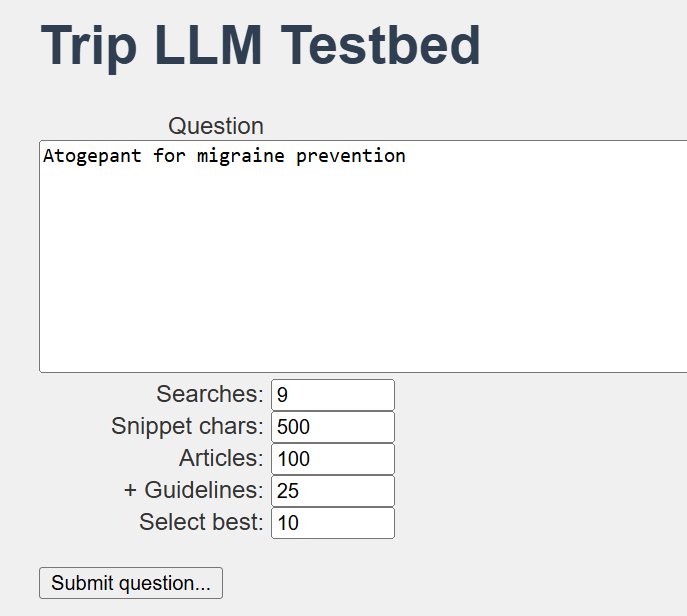
The underlying issue was our lack of visibility into what was happening under the hood. To truly understand the problem, we needed to build a test bed – something that would reveal what was going on at every stage of the process. This included:
The transformation of the question into search terms
The actual search results return
The scoring of each of the results
The final selection of articles to be included
The test bed looks like this and, while not pretty, it is very functional:
We were able to tweak and test a lot of variables, which gave us confidence in understanding what was really happening. So, what did we discover (and fix)?
Partial scoring by the LLM: While up to 125 results might be returned, the AI wasn’t scoring all of them – only about two-thirds. That’s why the Lancet paper was missing. Fix: We improved the prompt to ensure the LLM evaluated all documents.
Over-reliance on titles: When we only used titles (without snippets), we often missed key papers – especially when the title was ambiguous. Fix: We added short snippets, which solved the issue and improved relevance detection.
Arbitrary final selection: If more than 10 relevant articles were found, the AI randomly selected which ones to include in the answer. Fix: We built a heuristic to prioritise the most recent and evidence-based content. This single change has significantly improved the robustness of our answers – and testers already thought the answers were great!
So, we’ve gone from a great product – built on a lot of assumptions – to an even greater one, now grounded in solid foundations that we can confidently stand behind and promote when it launches in early June.
Yesterday, I returned to my former workplace – Public Health Wales (PHW) – to meet with the evidence team and discuss Trip’s use of large language models (LLMs). It was a great meeting, but unexpectedly challenging – in a constructive way. The discussion highlighted our differing approaches:
Automated Q&A – focused on delivering quick, accessible answers to support health professionals.
PHW evidence reviews – aimed at producing more measured, rigorous outputs, typically developed over several months.
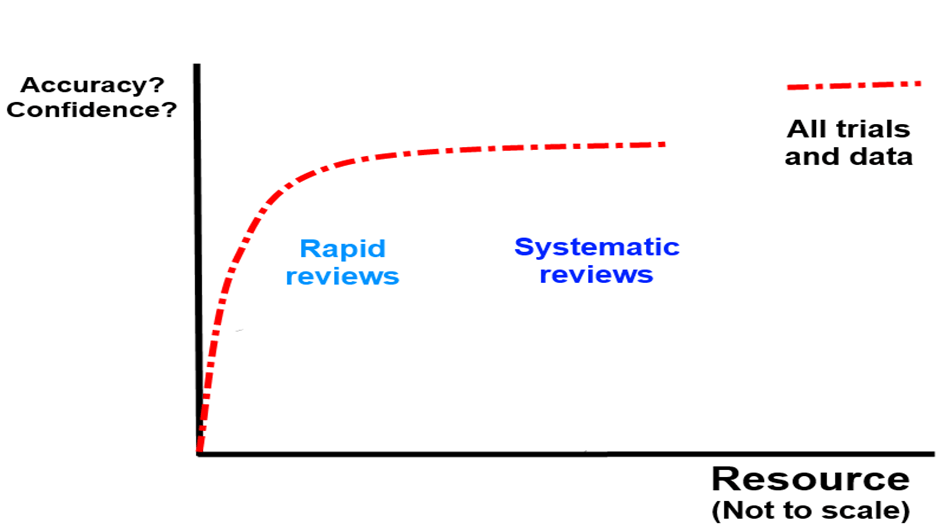
The conversation reminded me of when I first began manually answering clinical questions for health professionals. Back then, I worried about not conducting full systematic reviews – was that a problem? Over time, I came to realise that while our responses weren’t systematic reviews, they were often more useful and timely than what most health professionals could access or create on their own. Further down the line, after many questions, I theorised that evidence accumulation and ‘correctness’ probably looked like this:
In other words you can – in most cases – get the right answer quite quickly and then after that it becomes a law of diminishing returns… In the graph above I would include Q&A in the ‘rapid review’ space.
Back at PHW, their strong reputation – and professionalism – means they’re understandably cautious about producing anything that could be seen as unreliable. Two key themes emerged in our discussion: transparency and reproducibility. Both are tied to concerns about the ‘black box’ nature of large language models: while you can see the input and the output, what happens in between isn’t always clear.
With their insights and suggestions, I’ve started sketching out a plan to address these concerns:
Transparency ‘button’ – While this may not be included in the initial open beta, the idea is to let users see what steps the system has taken. This could include the search terms used and which documents were excluded (from the top 100+ retrieved).
Peer review – Our medical director will regularly review a sample of questions and responses for quality assurance.
Encourage feedback – The system will allow users to flag responses they believe are problematic.
Reference check – We’ll take a sample of questions, ask them three separate times, and compare the clinical bottom lines and the references used.
This last point ties directly to the reproducibility challenge. We already know that LLMs can generate different answers to the same question depending on how and when they’re asked. The key questions are: How much do the references and answers vary? And more importantly, does that variation meaningfully affect the final clinical recommendation? That might make a nice research study!
If you have any additional suggestions for strengthening the Q&A system’s quality, I’d love to hear them.
Two final reflections:
First, it was incredibly valuable to gain an external perspective on our Q&A system and to better understand their scepticism and viewpoint (thank you PHW).
Second, AI is advancing rapidly, and evidence producers – regardless of their focus – need to engage with it now and start planning for meaningful integration.





Recent Comments