Click here to try it now!
NOTE: The site is running a bit slow as the system is working hard on the translations!

Click here to try it now!
NOTE: The site is running a bit slow as the system is working hard on the translations!
It’s been a fantastic month for AskTrip — we’ve now handled over 1,400 questions! Even though we’re still early in the journey, we’ve already identified a number of ways to make AskTrip even better:
AskTrip en español – we’re currently testing this and hopefully it’ll be released sometime in August.
Helping When Evidence Is Limited
Coming soon (testing in August, possible release in September), a two-pronged approach when answers are limited by a lack of strong evidence:
Improving Answer Quality
We know quality is about more than just evidence:
Transparency
We’re committed to demystifying how AskTrip works — it’s essential for building trust. More on this soon.
Save Q&As
This has been requested by users, and we’ve taken note!
After all that?
We’re also thinking big – educational features, deeper evidence reviews, and new types of answers are all on the horizon.
And there’s one idea so ambitious we’re not even going to mention it yet – it sounds wild, but it just might be possible.
Thanks for being part of the journey
We’re learning fast, improving all the time, and always open to feedback. AskTrip is built to help you find answers you can trust — and we’re only just getting started.
Estará disponible pronto — qué tan pronto depende de cómo vayan las pruebas (It’s coming soon – exactly how soon depends on the testing!)


Over the weekend we started to rollout the RCT score:

One thing you might spot is that there are two different types of scores. The newer score are the top two and the older Risk of Bias score at the bottom. This will be in place for a few weeks as we overwrite the old method of scoring with the new one!
Each RCT will see a scale like this:

And if you click on the question mark on the right-hand side you’ll see a pop-up explainer:

As per previous scores, the use of scores is not without criticism – but clearly we feel it’s worthwhile – here’s an old discuss on the topic. Also, a significant drawback is that it’s based on abstracts. But the rationale is not to do a full critical appraisal but to help highlight potential problems with the trial. The user is then free to do a full appraisal.
Because AskTrip is still new, we’re actively reviewing all the answers it generates. When we find responses that fall short—not due to a lack of evidence, but because of verifiable process issues—we’re logging them.
Two recent examples include:
By tracking these problematic cases, we hope to identify patterns and ultimately improve the service.
If you ever come across an answer you believe is problematic, please let us know by emailing quality@tripdatabase.com
While much of our attention is focused on AskTrip we are still working on other aspects of Trip and one thread is introducing a score for RCTs. We already have a risk of bias score but it has been increasingly difficult keeping this up to date. So, time to do our own in-house one. It will look like this:

It looks like our existing scores for guidelines and systematic reviews but will be powered by LLMs. And, as with the systematic review score, it will be based on the trial abstract.
Take this trial: Occupational therapy improves social participation of complex patients discharged from hospital: results of a powered randomized controlled trial. Using our prompts we were able to generate an overall score of ‘good’ (this is just our in-house terminology) and we generated these strengths and weaknesses:
Strengths
Limitations
When we roll this out, the above text will be available when a user clicks the question mark (far right on the image).
As per previous scores, the use of scores is not without criticism – but clearly we feel it’s worthwhile – here’s an old discuss on the topic.
This will be a gradual rollout starting with the most recent trials first.
At the top of this post I mentioned that this wasn’t directly linked to AskTrip, the reality is that it can be. In the medium term, we can factor in the quality of guidelines, systematic reviews and RCTs when answering a question. That would be rather special!
Maybe not lots of fun, but I enjoyed doing it! At AskTrip we automatically assign clinical categories and also the strength of evidence used to answer the question. Put these together and you can – fairly – easily see what evidence is used to answer the questions.
I restricted it to a handful of the clinical areas where we had lots of questions (50+) and I’ve plotted it using two graphs (not sure which is best)
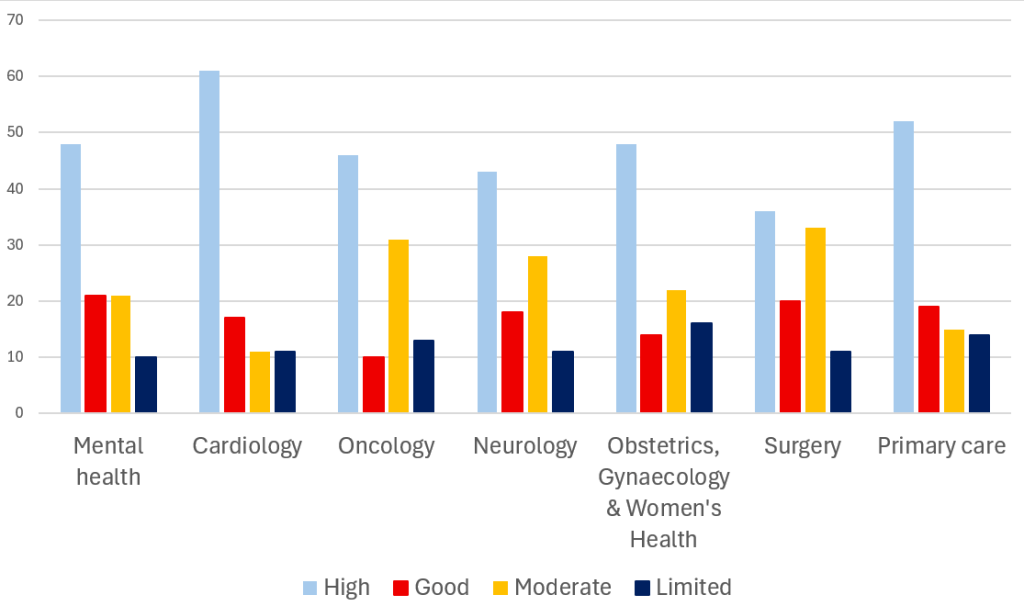
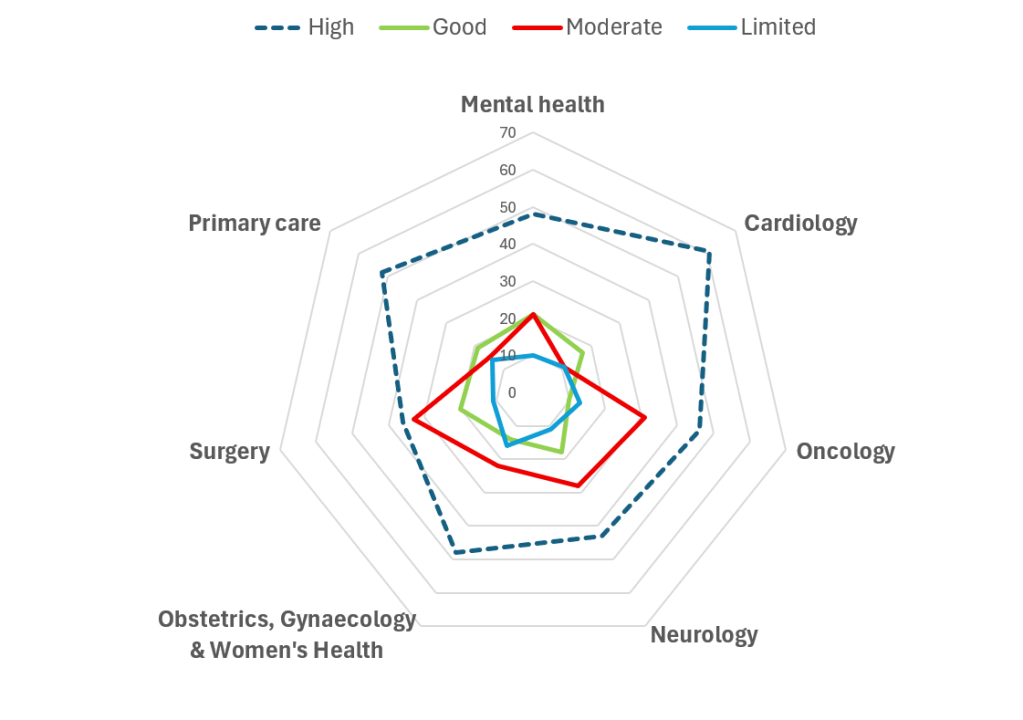
What we can see is that the cardiology questions we received we able to be answered with the most robust evidence (rating of high) and that was 61% (surgery was the worst with 36%)
Surgery and oncology are tied – with 44% – of the questions being answered with lower quality evidence (rating of limited or moderate) with cariology the best 22%
I called it fun as there are all sorts of methodological issues with the analysis – so take it with a pinch of salt…
AskTrip launched just over two weeks old and we’ve already had over 600 questions – it’s been brilliant…. However, we’ve recognised two changes we’d like to make.
Spanish Language

We’re developing a Spanish-language version of the site, enabling users to ask questions in Spanish and receive answers in Spanish. To support this, we’ll duplicate the existing site and translate all content, including previously asked questions. If the launch proves successful, we plan to expand the platform to support additional languages. (see our earlier post Apoyando el uso del idioma español en Trip Database).
Limited Answers
We rate all answers based on the strength of the evidence used — High, Good, Moderate, or Limited (click here to understand our approach). Here’s the current breakdown:
636 total Q&As
That means over a third of the questions have little supporting evidence. Interestingly, in the early days of manually answering clinical questions, clinicians often found it reassuring when no evidence was available – it confirmed that their uncertainty was valid.
Now, we’re exploring two ways to uncover more evidence:
I’m genuinely excited about both the Spanish-language launch (as a Hispanophile, it’s a no-brainer!) and these new ways to broaden the search. With a bit of luck, both features will roll out this summer.
At AskTrip, we are committed to protecting your privacy and using data responsibly. The following explains what information we collect, how we use it, and how we safeguard it.
What We Collect & Why
When you use AskTrip—either by logging in or accessing the service via IP authentication—we log your user ID (or institution ID) and IP address. This applies both when submitting questions and when viewing answers.
We collect this data to support service delivery, session management, usage monitoring, abuse prevention, and auditing. Question content and associated metadata are retained only as long as necessary for operational reasons (currently 90 days), unless selected for internal quality assurance or audit purposes.
Processing by Large Language Models (LLMs)
AskTrip uses external large language models (LLMs) to generate optimized search terms based on user-submitted questions. These models receive only the text of the question—we do not send login details, IP addresses, or any other user-identifying information.
However, if a user includes personally identifiable information (PII), such as a patient’s name or date of birth, this content will be sent to the LLM before AskTrip’s redaction layer can act. While the LLM may label such data as sensitive, it cannot be withdrawn once submitted.
Internal Query Handling
After the LLM generates search terms, all further processing happens securely within AskTrip’s systems. We search our internal clinical database (Trip Database), extract key clinical findings, and return an evidence-based summary to the user. No user-identifiable information is involved in this step, and no external systems access your data.
Analytics & Reporting
We use system logs, including user IDs, institution IDs, and IP addresses, to generate analytics reports that help us improve performance and understand usage trends. These reports are anonymized and aggregated.
Only authorized Trip staff can access raw log data, and it is never shared with external parties or visible to other users.
Use of Data for AI Development
We currently do not use any user-submitted data or usage logs to train or fine-tune AI models.
If this policy changes in the future, we will update this statement in advance and offer users the ability to opt out of such use.
Identity & Integration
AskTrip operates as a standalone service. It does not currently integrate with external identity providers such as Microsoft 365 or Google Workspace. User authentication is managed directly by AskTrip or through IP-based access provided by your institution.
Secure Access to Information Sources
AskTrip accesses only licensed or publicly available content from the Trip Database. All queries to our content sources are performed in read-only mode. No external system can access your queries or the content returned by AskTrip.
Data Security & Compliance
All data transmission is encrypted using industry-standard protocols (e.g., HTTPS/TLS 1.2+). Our hosting infrastructure is provided by Amazon Web Services (AWS), which is certified under standards such as ISO/IEC 27001 and SOC 2.
While the hosting platform meets these standards, the AskTrip application itself is not yet ISO/IEC 27001 certified—but we are actively working toward this. We comply with the UK General Data Protection Regulation (UK GDPR) and other relevant data protection laws.
Responsible Use
AskTrip is not intended to process or store sensitive personal data. We strongly advise users not to submit queries containing patient-identifiable information, such as names, dates of birth, or NHS numbers.
Clinical Decision-Support Disclaimer
AskTrip is designed to support – not replace – clinical decision-making. The information it provides is intended to aid professionals but does not substitute for individual clinical judgment.
This disclaimer applies to all users, including those who view previously answered questions, not just the original question submitter.
Enterprise Deployment Options
For institutional partners, AskTrip offers tailored deployments, including private hosting, single-tenant environments, data segregation, and custom retention policies, to meet specific governance, compliance, and security requirements.

Recent Comments