This post is an attempt to ‘think aloud’ about connected/related articles…. By that I mean, if you find an article you like how can you quickly find others that are similar. We know that searching is imprecise and a user might find articles that match their intention at say result #2, #7, #12 and then they may lose interest and miss ones at #54 or #97.
At Trip we have had something called SmartSearch for years. This mines the Trip weblogs to highlight articles that have been co-clicked in the same search session. So, if a user clicks on articles #2, #7 and #12 we infer a connection. We have successfully mapped these connections and it reveals a structure in the data. In the example below it’s a small sample of connections taken from searches for urinary tract infections:
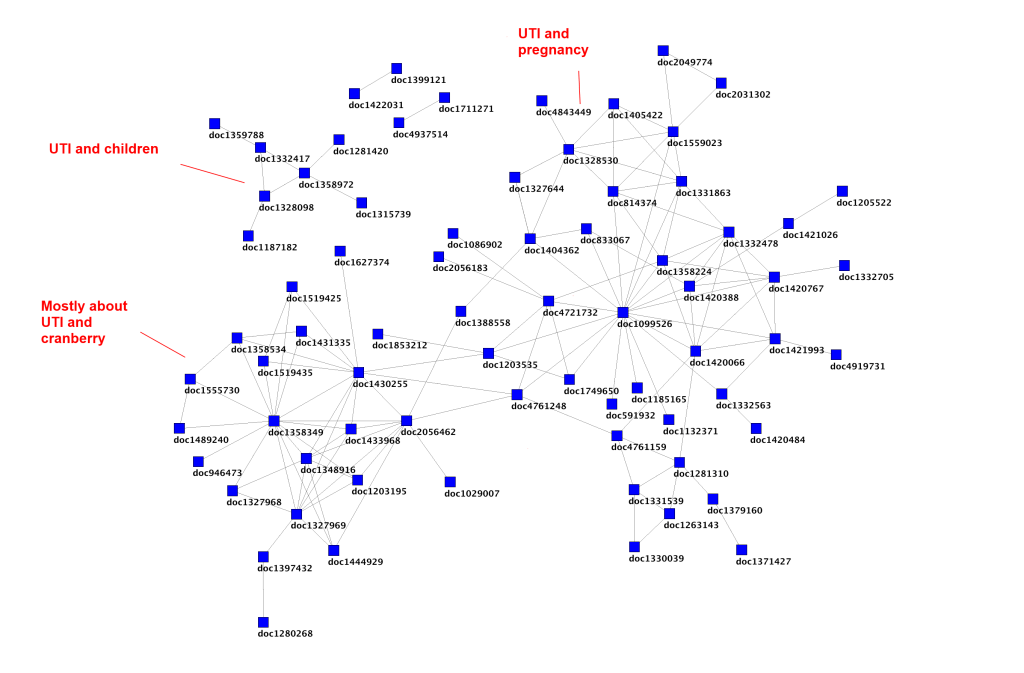
Each blue square represents a document and the lines/edges are connections made by co-clicking the documents within the same search session. You can see from the annotation that these form clusters around topics. However, co-clicking is not perfect!
Fortunately, there are other types of connections that I think we can use – semantic similarity and citations.
Semantic similarity: I’m thinking principally of PubMed’s related articles. This uses statistical methods to find articles with similar textual information e.g.

At the top is the document of interest and below are the articles deemed semantically similar. So, these articles are all related and one could make connections between them.
Citations: Articles typically list a bunch of references – so the article is citing these. And any article can itself be cited. So, you have forward and backward citations. Again, these have been shown as connections and mapped, e.g (source):
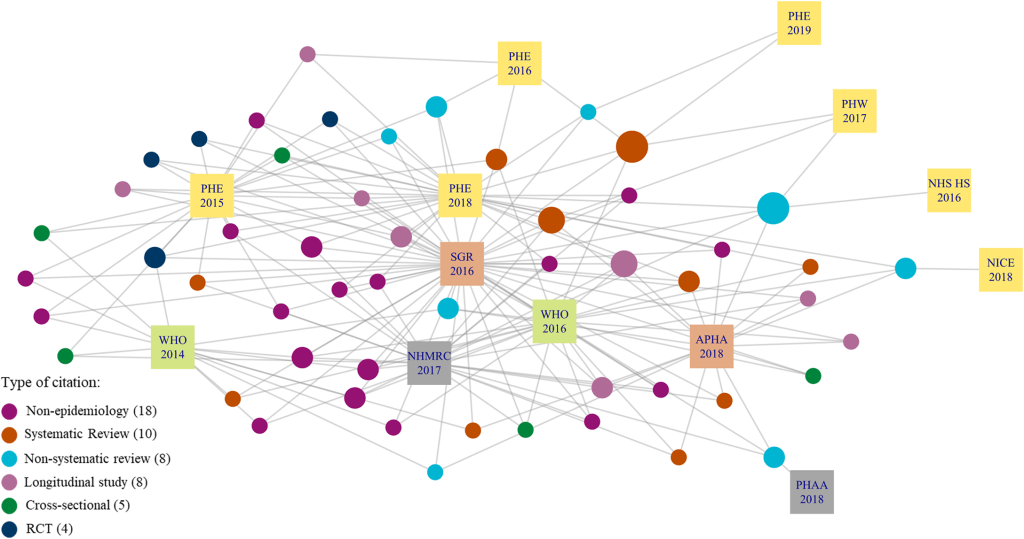
So, three types of connections: co-click, semantic similarity and citations. In isolation all have their issues but combined it could be something incredibly powerful. Well, that’s the theory….
While I believe SmartSearch is brilliant, I don’t think we’ve implemented it particularly well. The main issue I have is that a user needs to ‘call’ the results. On one hand that’s not a big deal but it looks like this:
I’ve highlighted it in red so you don’t miss it (an important issue in itself) but also it’s not really telling the user why they should click. In other words, it has a weak ‘call to action’. In part this is because it’s not ‘real time’ – a user clicks a button and the system calculates the related articles. I’m thinking if we told users that there were, say, 25 closely connected articles and 7 very closely connected articles, possibly teasing what these were, it would be much more compelling.
Another consideration, the notion of connected articles can work on two levels: the individual article and a collection of articles.
Individual articles: Each article within Trip could feature other connected articles be it co-clicks, semantic similarity or citations. It could be that we create a badge (thinking of the Altmetric Donut) that helps indicate to users how many connections there might be.
Collection of articles: If a user clicks on more than one article we, in effect, add up the information from the individual article data. This allows for some clever weightings to be brought in to highlight particularly important/closely connected articles.
But what information is important/useful to the user? I’m seeing two types of display:
List: A list of articles, arranged by some weighting to reflect ‘closeness’ – so those at the top are deemed closer to the article(s) chosen. We could enhance that by indication which are systematic reviews, guidelines etc
Chronological list: As above but arranged by date. The article(s) chosen would be shown and then a user could easily see more recent connected papers and also more historical papers. The former being particularly useful for updating reviews!
Right, those are my thoughts, for now. They seem doable and coherent but am I missing something? Could this approach be made more useful? If you have any thoughts please let me know either in the comments or via email: jon.brassey@tripdatabase.com
UPDATE
One excellent bit of feedback is to add connections between clinical trial registries and subsequent studies. This should be feasible. Similarly, link PROSPERO records (register of ongoing systematic reviews).
UPDATE TWO
Another excellent idea – add retraction data

1 Pingback